Python 模块
什么是模块
恭喜你坚持学到本章。此时的你已经不再是一个0基础小白了,你已经是一个Python的初学者了。你写的代码也不再是简单的hello world,而应该尝试写一些不那么简单的系统性工程,或者代码量较大的应用程序。然而,一个简单的Python文件在这种情况下已经过于臃肿,无法承担一个重量级别的�开发任务。因此,我们希望能够化繁为简,将功能模块化文件化,像搭积木一样,将不同的功能以组件化模块化的方式搭建起来。这就是本章要学习的一个新的知识点——模块。其实在前面的学习中,我们已经大量使用了。比如说time模块、random模块,使用它们的时候,我们直接使用关键字import,就已经导入了这些模块,然后就可以调用模块的一些方法和属性,极大地简化了我们的代码。
那么什么是模块呢?一个模块就相当于一个工具箱,如下图所示:
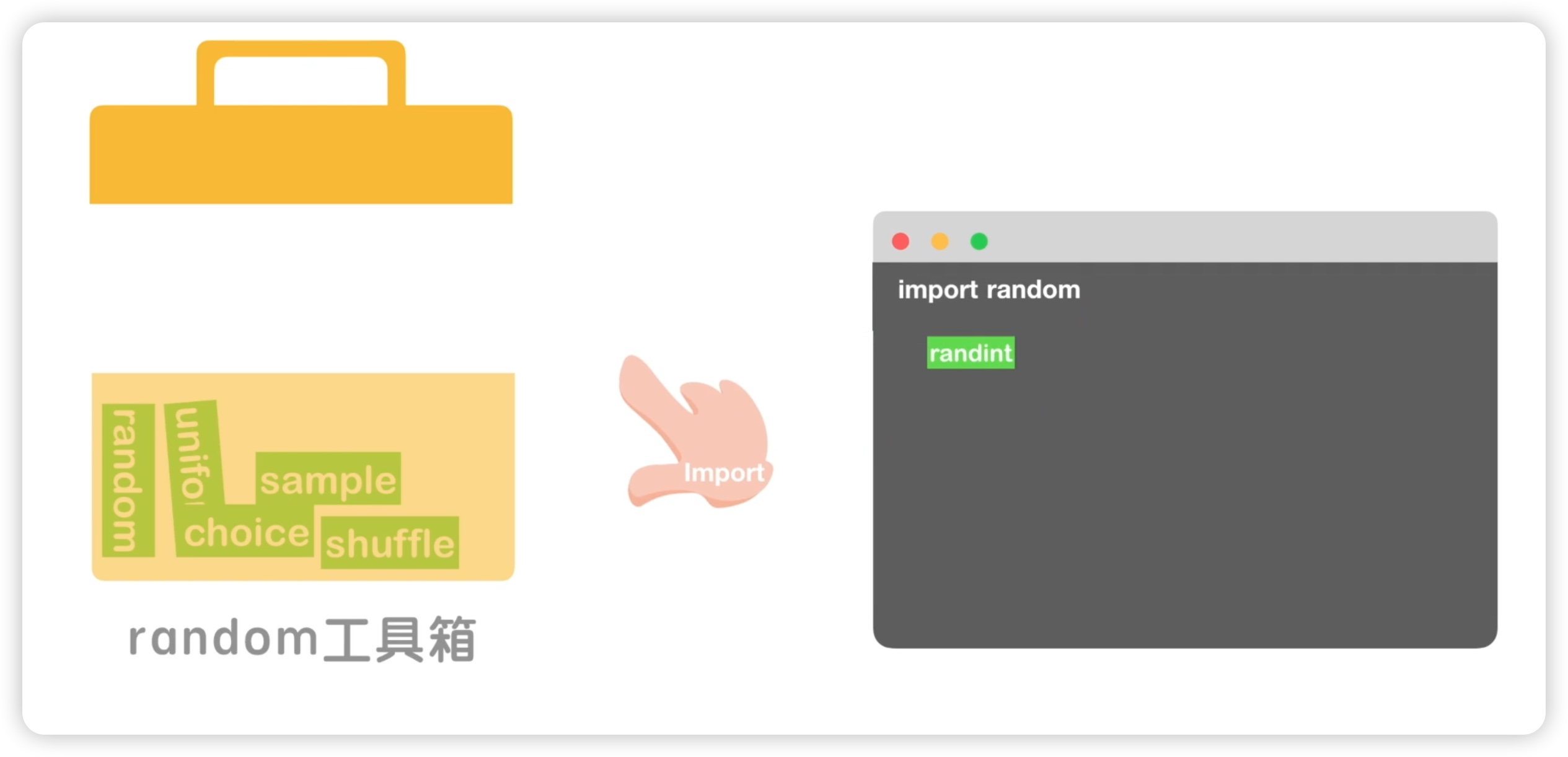
比如说我们前面使用的random模块,它就是一个工具箱,里面有非常多的工具。当我们要使用一个工具的时候,我们就从这个工具箱里取出一个工具,这里使用import把这个工具取出来,然后在使用的时候使用import random导入这个工具箱,接下来我们就可以使用工具箱里的工具了。
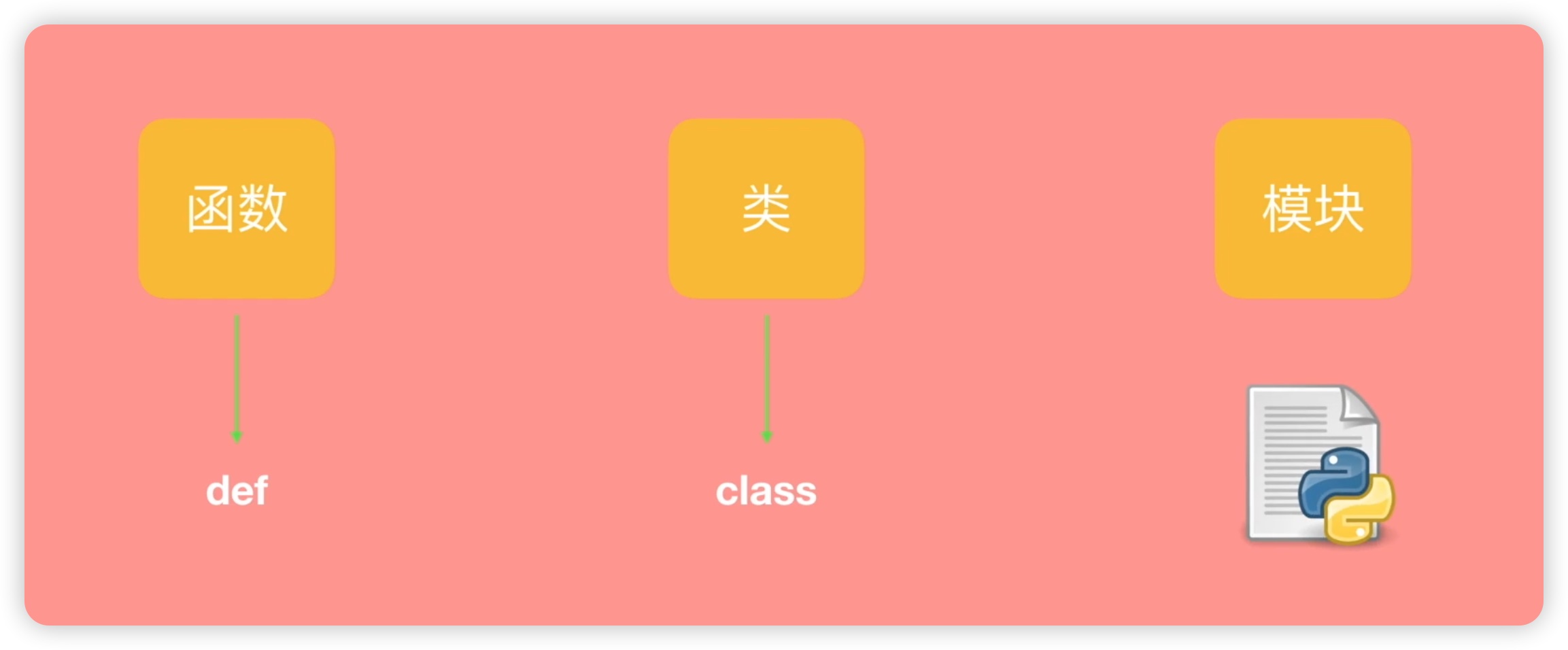
现在我们已经了解了模块,应该如何创建模块呢?比如说创建函数我们使用关键字def,创建类我们使用关键字class,其实,模块在代码中的形式就是一个Python文件,我们前面编辑的每一个Python文件,它都可以当做一个模块。如下图所示:
但是在实际开发过程中,我们通常会将一些实现了某一个特定功能的代码放置在一个Python文件中,然后把它当做一个模块。所以说,模块它是不需要创建的。比如说,在这里有三个Python文件,这三个Python文件中都使用了一个相同的功能,所以我将这个功能单独提出来,然后放到一个Python文件中,我就把��它称之为模块。如下图所示:

然后在其他Python文件中,当我需要实现这个功能的时候,我就调用这个Python模块。第二个Python文件也需要实现同样的功能,接着我们再来使用一套导入。从这个例子中我们就可以看到,模块的主要用途就是方便其他程序导入你的模块,并使用模块中的代码,这样就可以提高代码的可复用性以及可读性。此外还可以将一个很复杂的文件拆分为不同的模块,这样也是将代码进行模块化,这就是模块的作用。
模块的分类
在学习函数时,我们将函数大致分为两类。第一类是内置函数,即Python自带的函数,我们可以直接使用。第二类是自定义函数,根据个人需求定义的函数,被称为自定义函数。在本节,我们也来介绍一下模块的分类。模块可以大致分为三类。第一类是内置模块,与内置函数类似,是Python自带的。也就是说,当我们安装完Python后,就可以使用它的内置模块了,比如前面大量使用的time、datetime、random等模块,它们都是Python内置模块,由Python官方开发。要了解Python中的内置模块,可以通过Python官方文档查看,其中有一个叫做Python标准库的文档,全面介绍了Python中的内置模块。
在浏览器中地址输入:https://docs.python.org/zh-cn/3/library/index.html可以查看Python官方文档,如下所示:
我们这个页面查找一下time模块,使用快捷键ctrl+f,在搜索栏中输入time,页面往下翻,这里就是我们常用的time模块,它是属于操作系统服务的分类下面的,如下图所示:

我们点击看一下,这就是time模块,它的一些详细的介绍。

另外呢,time模块还有很多其它的方法,大家可以自行查看其他内置模块和它的方法。
Python内置模块虽然有很多,但都是一些比较常用的,不包括一些特定专业方向的模块,比如和web开发、机器学习、数据分析相关的模块。这些属于第三方模块,由热心的开发者或组织开发,并免费供给大家使用。要使用第三方模块,需要先下载,然后才能使用import导入。与内置模块不同的是,内置模块在下载完Python后就可以直接使用,无需额外下载。对于第三方模块的管理,有一个组织统一的管理平台,叫做PYPI(Python Package Index),类似手机应用商店,用户可以从中下载模块,开发者也可以将开发好的模块上传到其中供他人使用。最后,第三类是自定义模块,由我们自己编写的Python文件,实现特定功能。比如开发微信机器人自动回复的功能,可以将其拆分为多个模块,然后在主程序中导入相应的模块实现功能。如下图所示:

以上就是Python模块的分类,分为内置模块、第三方模块以及自定义模块。
import导入模块
前面我们已经介绍了模块的基础知识。我们知道,在代码中要导入模块,需要使用关键词import。接下来,我们将在代码中演示如何使用import来导入模块。
首先创建一个Python文件,命名为main.py。我们先介绍最简单的导入方式,即使用import来导入一个内置模块,比如time模块。导入完time模块后,我们可以调用其中的方法。例如,我们可以调用计算时间的方法,比如perf_counter。调用方法的方式与我们学习面向对象时调用属性和方法的方式相同,即使用time.后跟着方法名称,代码如下:
import time
start = time.perf_counter()
在一个文件中,我们还可以调用多个模块。比如,我们接着调用和系统函数相关的os模块。多个模块之间可以用逗号进行分割,但根据PEP8的标准,通常我们在调用模块时,每一个模块之间单独调用一次import。例如,我需要调用os模块中的一个名为listdir的方法,以显示当前路径下的所有文件。代码如下:
import time
import os
start = time.perf_counter()
print(os.listdir())
接下来,我会输出系统的运行时间,即end减去start。代码如下:
import time
import os
start = time.perf_counter()
print(os.listdir())
end = time.perf_counter()
print(end-start)
输出结果:
['main.py']
7.07090000000004е-05
我们看到的输出结果是调用os模块下的listdir方法来显示当前目录下的文件。在这个例子中,当前文件夹下只有一个文件,即main.py,因此输出结果只包括main.py。下面的输出是运行时间。这就是调用模块的方法。
另外,我们还可以给模块起一个别名,以防止不同模块之间的冲突。例如,要实现读取不同类型的文件操作时,可以导入名为xml reader的模块以读取XML文件,或者导入名为csv reader的模块以读取CSV文件。代码如下:
# 设置一个变量format为字符串'xml'
format = 'xml'
# 检查format是否等于'xml'
if format == 'xml':
# 如果是'xml',则导入xmlreader模块
import xmlreader
# 调用xmlreader模块中的read_data函数
xmlreader.read_data()
else:
# 如果不是'xml',则导入csvreader模块
import csvreader
# 调用csvreader模块中的read_data函数
csvreader.read_data()
虽然这个功能没有问题,但代码看起来有些冗长。针对这种情况,我们可以使用别名来简化代码。例如,在导入xmlreader时,我可以使用as关键字给它起一个别名,比如reader。在调用时,我们可以使用这个别名来代替原始的xmlreader。同样地,我们可以为csvreader也起一个别名,并在调用时使用这个别名。代码如下:
# 设置一个变量format为字符串'xml'
format = 'xml'
# 检查format是否等于'xml'
if format == 'xml':
# 如果是'xml',则导入xmlreader模块
import xmlreader as reader
# 调用xmlreader模块中的read_data函数
reader.read_data()
else:
# 如果不是'xml',则导入csvreader模块
import csvreader as reader
# 调用csvreader模块中的read_data函数
reader.read_data()
我们可以将这两个reader.read_data()代码段提取出来,移至if语句之外,从而使代码更加规范。代码如下:
# 设置一个变量format为字符串'xml'
format = 'xml'
# 检查format是否等于'xml'
if format == 'xml':
# 如果是'xml',则导入xmlreader模块
import xmlreader as reader
else:
# 如果不是'xml',则导入csvreader模块
import csvreader as reader
reader.read_data()
这种情况下,别名的作用就显而易见了。此外,当模块名称比较长时,我们可以给它起一个更短的别名,以提高代码的可读性。例如,对于数据分析中经常使用的pandas模块,通常会使用更短的名字pd来代替。这也是别名经常被使用的一种情况。
综上所述,使用import语句主要有两种方式:一是直接导入模块名称,然后调用模块方法;二是使用as关键字复制一个别名,然后通过别名来调用相关的属性和方法。
from-import导入模块
在上一节课程中,我们学习了使用import语句来导入一个模块。然而在Python中还有另一种更为常见的方式,叫做from import,它允许从模块中直接导入相应的内容。由于这种语法比较简单,我们直接通过代码来学习一下。我们打开上一节课程中用到的代码。代码如下:
# 导入time模块
import time
# 导入os模块
import os
# 记录开始时间
start = time.perf_counter()
# 打印当前目录下的所有文件
print(os.listdir())
# 记录结束时间
end = time.perf_counter()
# 打印运行时间
print(end - start)
我们对其进行修改,使用from import方式来导入模块中的内容。代码如下:
from time import perf_counter
from os import listdir
# 记录开始时间
start = time.perf_counter()
# 打印当前目录下的所有文件
print(os.listdir())
# 记录结束时间
end = time.perf_counter()
# 打印运行时间
print(end - start)
导入完成后,我们就可以直接使用导入进来的名称,而不需要再使用模块名称来调用。代码如下:
# 从time模块中导入perf_counter函数
from time import perf_counter
# 从os模块中导入listdir函数
from os import listdir
# 记录开始时间
start = perf_counter()
# 打印当前目录下的所有文件
print(listdir())
# 记录结束时间
end = perf_counter()
# 打印运行时间
print(end - start)
输出结果:
['from_import.py','main-py']
7.445600000000052-05
结果是一样的,可以正常输出。现在,listdir函数的输入是两个文件了,一个是main,另一个是from import。
在之前介绍import时,我们提到可以使用别名。同样地,from import也支持使用别名。例如,在导入perf_counter时,如果觉得这个名字比较长,我们可以这样:from time import perf_counter as counter,这样就给它起了一个别名。在调用时,我们可以通过这个别名来使用。
此外,如果我们需要从time模块中调用多个方法,可以使用逗号进行分割。举例来说,time模块中有一个sleep方法,可以用来使程序休眠一段时间。比如,我们可以让程序休眠一秒钟,即sleep(1),然后再执行下面的代码。代码如下:
# 从time模块中导入perf_counter函数,sleep
from time import perf_counter as counter ,sleep
# 从os模块中导入listdir函数
from os import listdir
# 记录开始时间
start = counter()
sleep(1)
# 打印当前目录下的所有文件
print(listdir())
# 记录结束时间
end = counter()
# 打印运行时间
print(end - start)
我们运行一下程序,这时程序的执行时间就会延长一秒钟左右,因为在这里发生了一段停顿。因为我们使用了sleep方法,导致系统等待了一秒钟。一秒钟过后才会继续执行下面的代码。如果后面还调用了time模块的其他方法,同样我们可以使用逗号,然后加上模块名称,比如strftime等等。如果想调用time模块下的所有方法,可以使用*号来代替。这个*号表示调用下面的所有方法。代码如下:
from time import *
在实际的编码过程中,我们很少会使用这种方式,因为time模块下有很多的方法。如果某个方法的名称与其他模块下的方法名称重名了,就会造成冲突,而且这个错误很难发现。因此一般情况下我们很少会全部导入所有方法。
总的来说,from import的常见方式有三种:第一种是从模块中导入某个具体的方法;第二种是可以使用别名的方式加一个as进行别名定义;第三种是导入多个方法或者是全部方法,如果是多个方法,那么就用逗号来进行分割,如果是全部方法,就用一个*号。
导入自定义模块
在之前的部分,我们已经学习了如何导入内置模块。而在本节中,我们将介绍如何导入自定义模块。接下来,我们将通过代码演示如何导入自定义模块。
首先我们需要创建一个名为 "function" 的python文件。我们已经了解到,在Python中,模块的形式就是一个.py文件。因此,这个 "function" 文件就可以作为一个模块。在这个文件中,我们将编写一些常用的功能,比如定义一些函数。代码如下:
# 定义一个函数add,接受两个参数x和y,返回它们的和
def add(x, y):
return x + y
# 定义一个函数subtraction,接受两个参数x和y,返回它们的差
def subtraction(x, y):
return x - y
模块的定义完成后,我们将展示如何调用它。我们再创建一个名为run.py的Python文件。现在,我们想要调用 "function" 模块,如下图所示:
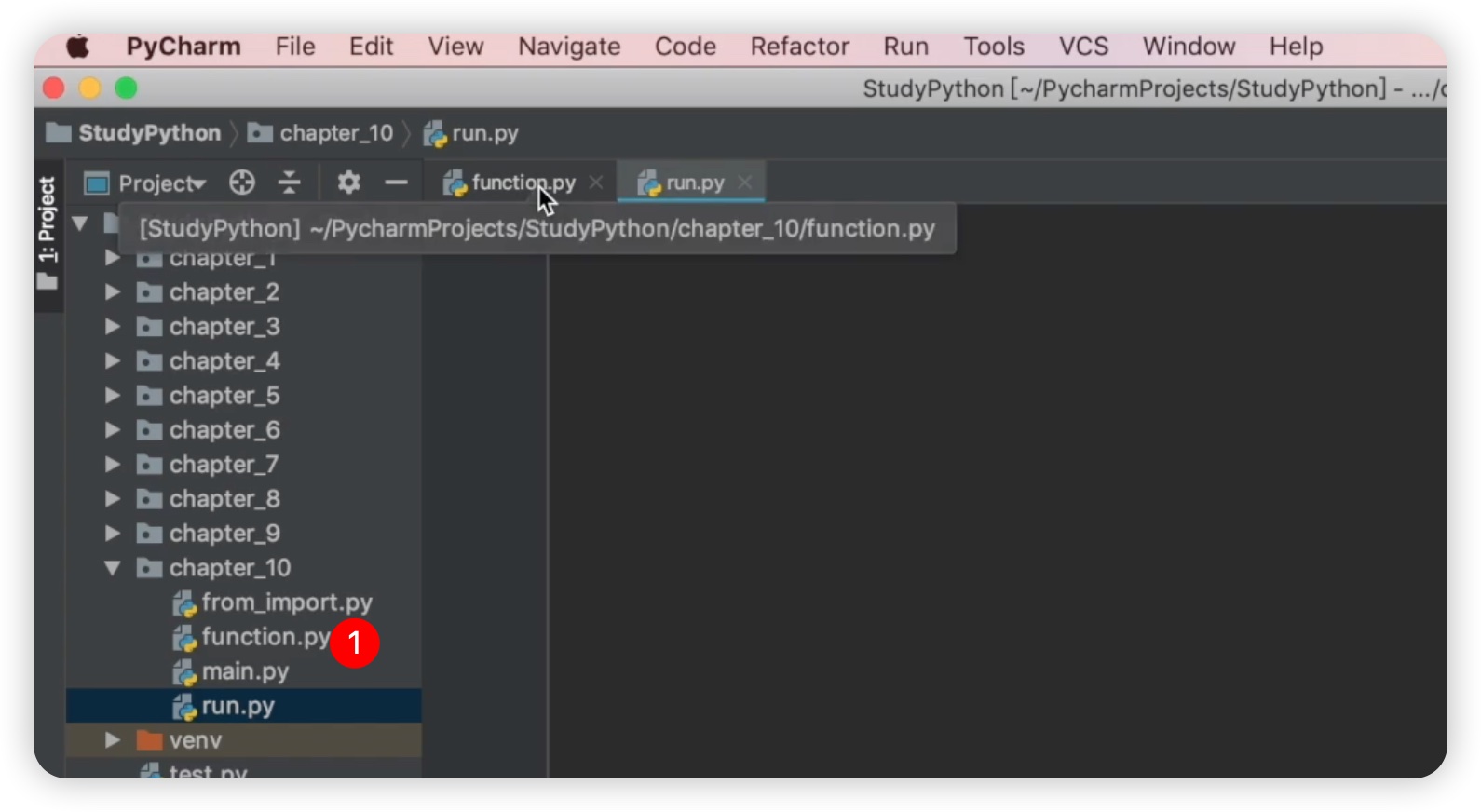
那么我们需要在run.py文件中先导入这个模块,使用 import 关键字加上模块名 "function"。然后,我们可以调用 "function" 模块中的方法,例如 function.add,并给它赋予两个值,然后打印输出结果。代码如下:
import function
sum = function.add(1,2)
print(sum)
运行代码,输出结果为3,没有问题。这是使用 import 来导入模块的方式。除了使用 import 外,我们还可以使用 from...import 的方式来导入模块。从 "function" 模块中导入 add 方法。导入完成后,在调用方法时,就不需要再写前缀模块名了,直接使用 add 进行调用。代码如下:
from function import add
sum = add(1,2)
print(sum)
结果仍然为3,这种方式也是可以的。
接下来,我们增加一点难度,将这些函数放到另一个文件中。比如说,我们在当前目录下创建一个名为utils的文件夹,然后将这些函数放到里面。我们可以直接拖动函数文件到这个文件夹里,系统会提示是否移动,点击“OK”即可完成移动。如下图所示:
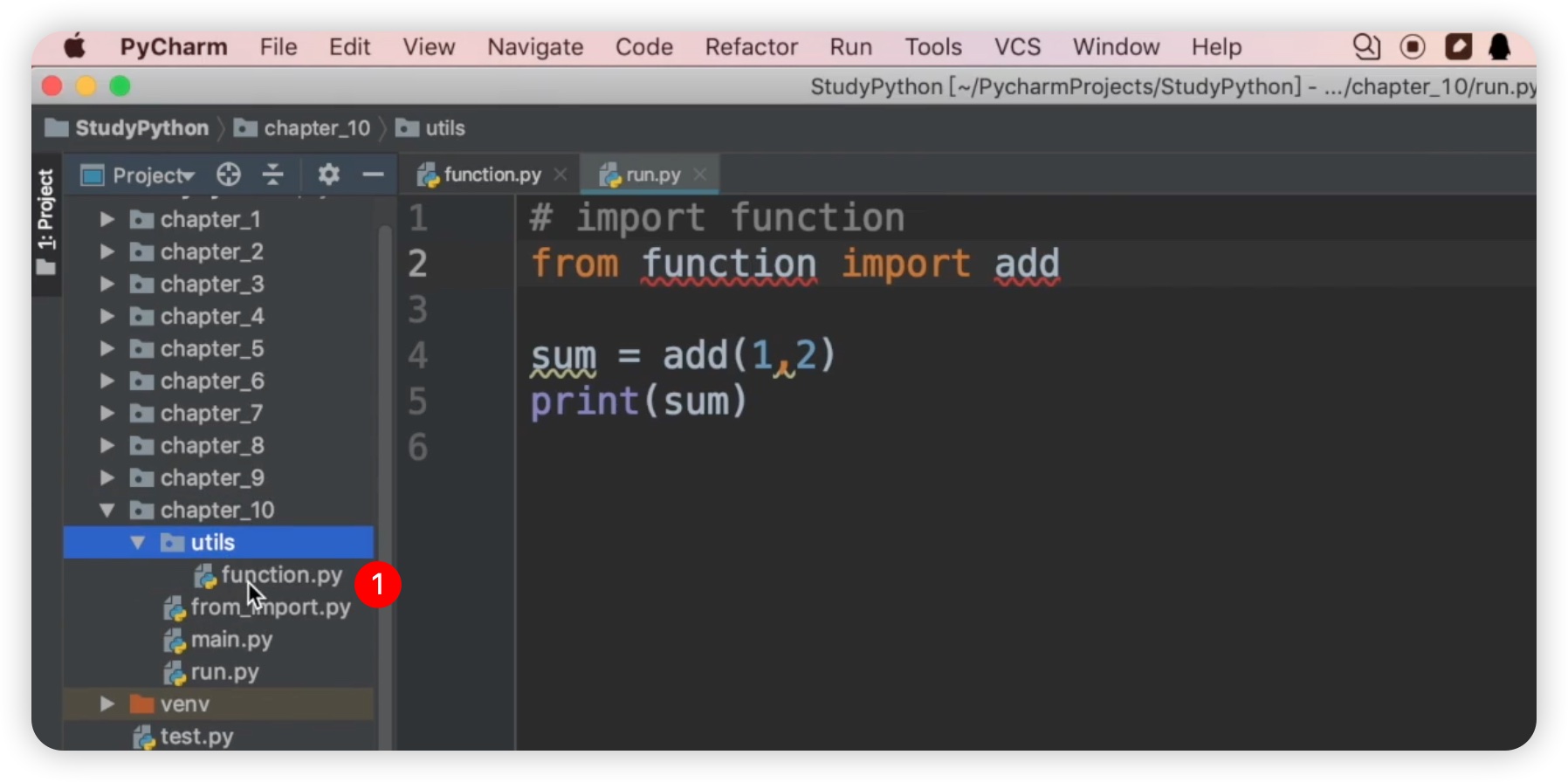
然而,如果现在在run.py中调用这个模块,肯定是行不通的。让我们来试一下,此时会提示找不到这个模块no model name.function。因为现在function.py已经不在run.py的同级目录下了,而是在utils下面了,所以我们不能直接这样调用了。我们修改代码如下:
from utils.function import add
sum = add(1,2)
print(sum)
再尝试运行一下,现在是可以正常输出的。如果想使用import来调用呢?那要如何找到这个模块呢?这时候我们就需要了解一个知识点,叫做模块的查找路径。我们可以通过一个模块sys来查看模块的搜索路径。首先,导入import sys,然后使用sys.path来输出搜索路径。代码如下:
import sys
print(sys.path)
输出结果:
['/Users/andy/PycharmProjects/StudyPython/chapter_10'
'/Users/andy/PycharmProjects/StudyPython',
'/Library/Frameworks/Python.framework/Versions/3.7/lib/python37.zip', '/Library/Frameworks/Python2
framework/Versions/3.7/Lib/python3.7', '/Library/Frameworks/Python.framework/Versions/3
S.7/lib/python3.7/lib-dynload',
S.7/site-packages'
S.7/site-packages/setuptools-40.8.0-py3.7.egg'
、く
/lisers/andv/PvcharmProiects/StudvPvthon/venv/1ib/nvthon3.7/site-nackages/nin-19.0.3-nv3.7.eaa']
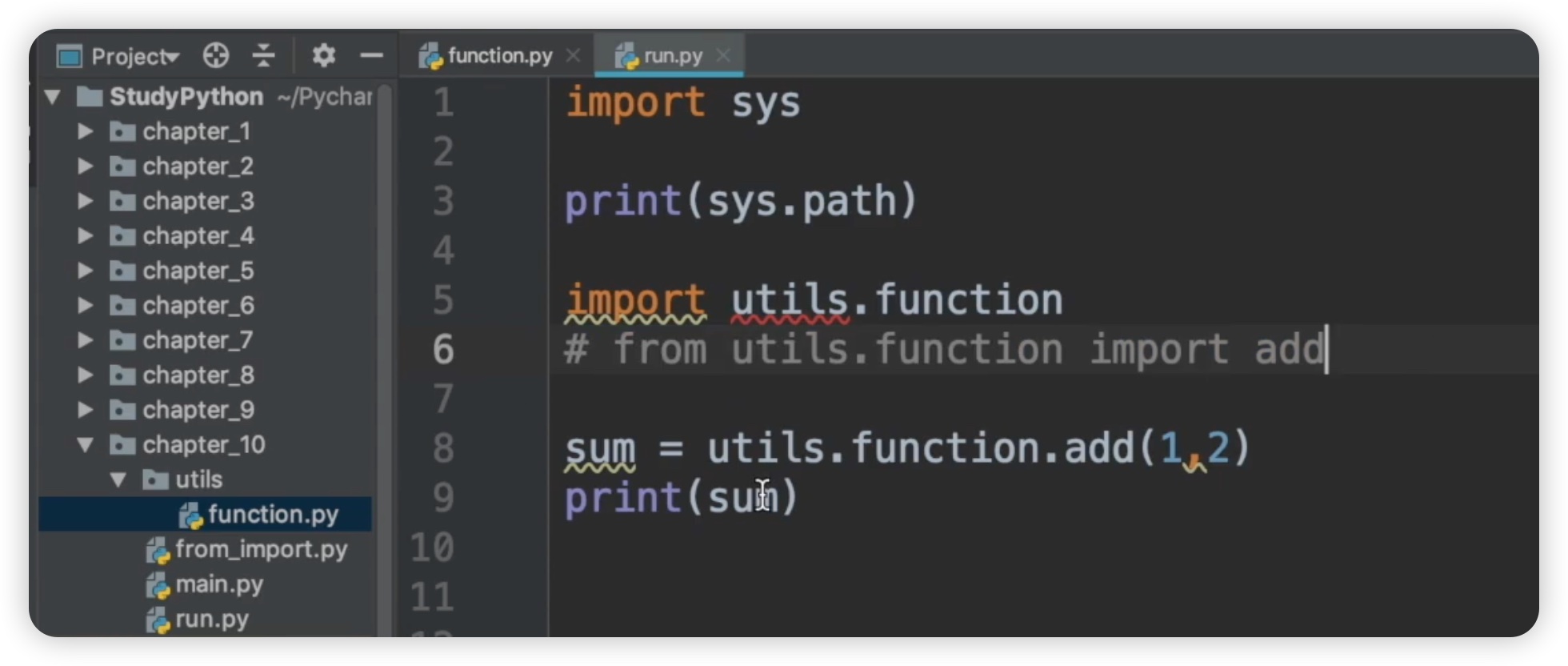
我们可以看到输出结果是一个列表,在导入模块的时候,是按照这个路径列表的顺序来查找的。因此,我们可以从第一个元素开始查找,即当前目录chapter 10,然后通过这个路径来找到utils,再找到function。所以在导入的时候我们使用import utils.function,修改代码如下:
import sys
print(sys.path)
import utils.function
#from utils.function import add
sum = utils.function.add(1,2)
print(sum)
现在结果就可以正常输出了,它的结果是3。在大多数情况下,我们更倾向于使用from import这种方式,因为它的可读性更高。
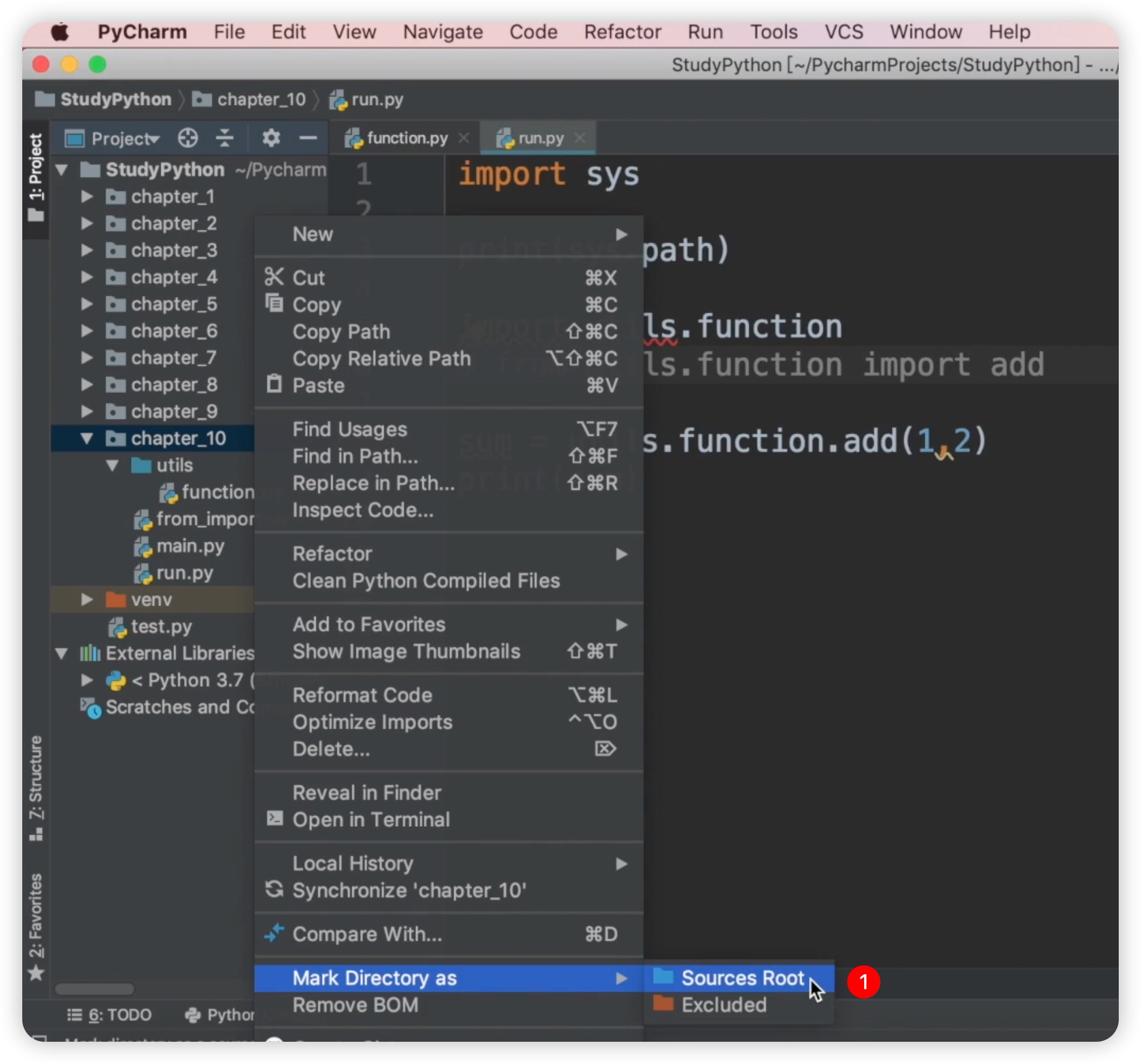
此外,还有一点容易让大家困惑的地方,就是为什么会出现红色的波浪线,但是程序却可以正常运行呢?如下图所示:
这个红色波浪线是由PyCharm提供的错误检测功能。虽然大多数情况下,如果PyCharm提示错误,程序是无法正常运行的,但这并非�绝对。比如说,即使出现错误提示,有时程序仍能正常运行。然而有些人可能觉得这个红色波浪线看着别扭。这时,可以使用一个小技巧来去掉这个红色波浪线。鼠标右键单击目录chapter10,然后选择“Make Directory as” -> “Source Root”,这样就把它当作资源的根目录。选中后,红色波浪线就消失了,但程序仍然可以正常运行。这种方式能提高代码的可读性。如下图所示:
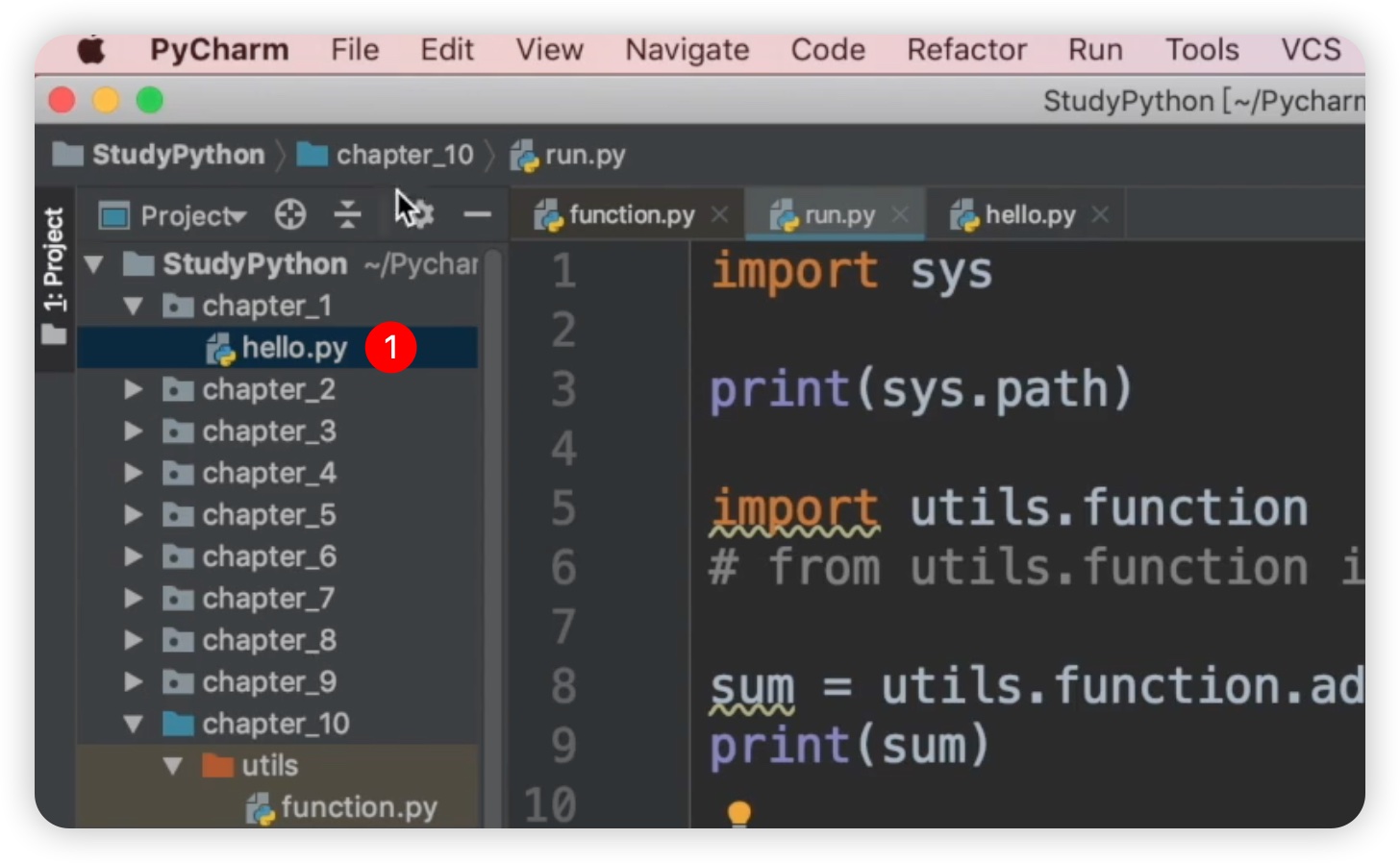
现在我们导入的是在chapter10文件夹下的所有文件。此外,我们还可以导入其他文件夹下的文件,比如说chapter1。我们可以导入chapter1下面的hello.py,代码如下:
import sys
print(sys.path)
import utils.function
# from utils.function import add
sum = utils.function.add(1,2)
print(sum)
from chapter_1 import hello
j结果输出hello world。为什么我们可以导入chapter1呢?这是因为在导入chapter1时,同样是按照搜索路径来查找的,从第一个元素开始找,即studyPython。在studyPython下有chapter1,所以可以导入。如下图所示:
导入hello后,它会自动执行其中的代码,因为hello.py中有一个print语句,所以会输出hello world。
但是,为什么我们在导入add时没有正常输出呢?这是因为它是一个函数。对于函数或类的定义,虽然它们被定义了,但是不会自动执行,只有在调用时才会执行。除了函数外,类也是一样的道理。当你定义了一个类,它也不会自动执行,只有在实例化时才会执行。
总结一下:如果想要调用一个自定义模块,首先需要知道该模块所在的路径。如果是同级路径,可以直接进行调用。如果不在同级路径下,则需要使用sys.path来查看搜索路径。如果在搜索路径下,就可以直接导入。如果不在搜索路径下,就会报错,提示模块不存在。此外�,在导入模块时,会执行其中的代码,但对于函数和类的定义,则不会自动执行,只有在调用时才会执行。
import 与 from-import的区别
本节我们来学习一下import和from import之间的本质区别。
假设有一个名为test.py的文件,我们需要导入一个名为m.py的模块。当我们使用import来导入时,相当于在test.py中创建了一个与m.py同名的m对象,我们可以通过这个m对象来调用模块中相应的属性和方法。因此,使用import导入模块时,会将整个模块对象赋值给一个同名的变量。如下图示:

举例来说,如果模块文件名为my_module.py,那么在test.py中,就会创建一个名为my_module的对象。当然,我们也可以使用as关键字为其赋一个别名,然后通过别名来调用属性和方法。这就是import的运行原理。
然后,让我们来看一下from import。同样地,在test.py文件中要调用m.py这个模块。现在我们使用from import,它调用的是m.py中的某个或者是某几个属性。如下图所示:

例如,我们调用了m.x和m.y,那么就相当于将m.x和m.y分别赋值给test.py中的变量x和y,然后我们可以对这个x和y进行操作。需要注意��的是,这里导入的时候并不是全部导入,而是只导入了某个或者是某几个属性。导入后,相当于将m.x和m.y分别复制给了同名的变量x和y。换句话说,就是将一个或多个变量名赋值给同名的对象。
接下来,我们在代码中来演示一下它们之间的区别。我们创建一个模块文件m.py,在里面写一些奇怪的代码,代码如下:
print("this is m.py file")
x = 1
y = [1,2]
在实际应用中,我们并不会创建这样的模块,这里只是为了更好地理解模块的工作原理。创建好m之后,我们再创建一个调用者文件test.py。在test.py中,我们首先导入m.py,使用import,即import m。导入完成后,相当于创建了一个同名的对象。因为这里的m.py和m它们的名字是一样的。接着我们可以打印一下这个对象。代码如下:
import m
print(m)
输出结果:
this is m.py file
<module 'm'from '/Users/andy/PycharmProjects/StudyPython/chapter_10/m.py'>
当我们运行时,它会输出两行语句,第一行是this is m.py file,这是在m.py中输出的。而第二行则是我们在test.py中输出的print语句。这说明了模块的一个特点,即当我们导入模块时,程序会执行m模块中的代码。m模块的第一行代码是输出,所以它就输出了。接下来两行代码是赋值语句,所以它也会进行赋值。这就是对于模块的一个基本认识。我们可以通过type函数来输出模块的类型,也可以更直观地使用type(m)来查看。
我们还可以使用dir函数来查看模块有哪些属性。代码如下:
import m
print(m)
print (type(m))
print(dir (m))
输出结果如下图所示:

可以看到一个列表,其中包含了模块的所有属性。最明显的属性是x和y,因为它们是在m模块文件中定义的。当我们导入后,模块对象就拥有了这些属性。此外,还会有一些双下划线开头的属性,这些是模块的内置方法。其中有一个__name__属性,我们可以通过print(m.__name__)来运行,它表示模块的名称,输出结果为m。
接着,我们再输出一下__name__,即当前文件的名称,代码如下:
import m
print(m)
print (type(m))
print(dir (m))
print(m.__name__)
print(__name__)
结果是__main__。这说明当前这个test.py文件的名称是__main__。这个信息为后面的课程埋下了伏笔。这是使用import导入模块的方法,导入后相当于创建了一个同名的对象,然后我们可以通过这个对象调用相关的属性和方法。
接下来,我们再看一下在test.py文件中使用from import的情况。我们看到模块中有x和y,我们就将它们导入进来。代码如下:
from m import x,y
print(m)
导入完成后,我们尝试输出m,结果提示name 'm' is not defined,这说明并没有导入m模块,而是从m模块中导入了两个属性x和y,并将它们赋值给了test.py文件中的x和y。我们可以输出x,也可以输出y,但是不能输出m,而是输出m中的两个属性。因此,它就等价于将m.x赋值给变量x,将m.y赋值给变量y。如下图:
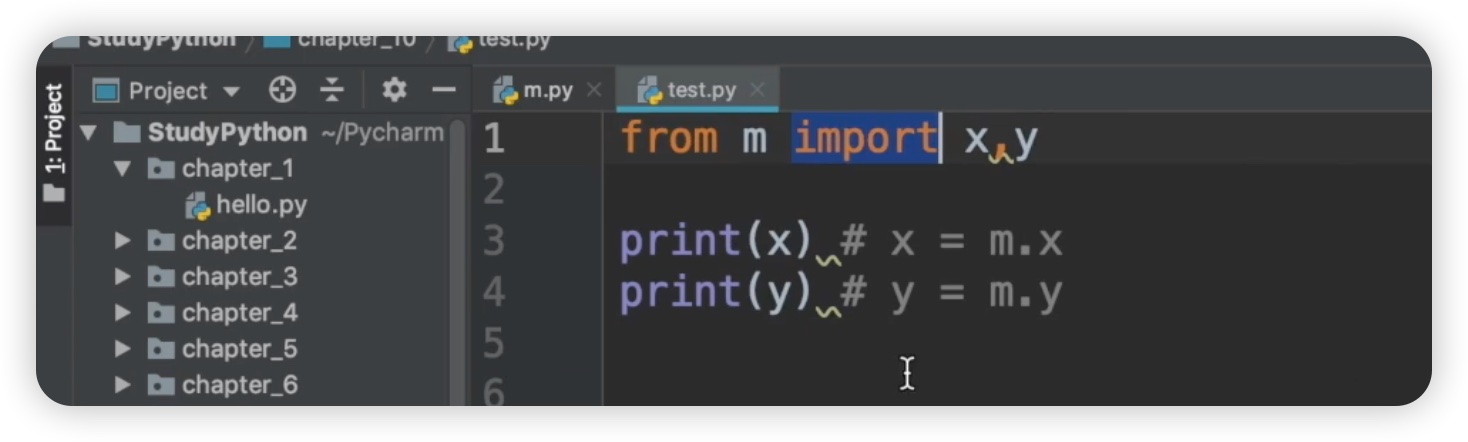
此外,需要注意的一点是,当我们使用from import导入时,也会执行m.py文件,因为我们看到这里依然输出了this is m.py file。
接下来,我将为变量x赋值为100,并尝试在此后调用它,代码如下:
from m import x,y
print(x)
x = 100
print(x)
输出结果:
/Users/andy/PycharmProjects/StudyPython/chapter_10/test.py
this is m-py file
1
[1,2]
100
在执行代码后,x的值已经发生了变化,变成了100。这是因为在这里声明的变量会覆盖之前的变量。类似地,如果我将变量y也赋值为100,然后输出它,结果会发现原来的y是一个列表,但现在被赋值为100。因此,在使用from import语句时,会覆盖掉原来的值。然而,如果我不覆盖这里的y,而是修改它,代码如下:
from m import x,y
print(x)
x = 100
print(x)
y[0] = 100
print(y)
再来看一下运行结果,此时y就变成了一个包含100和2的列表。因为只是列表中的第一个元素被修改了,而y自身并没有被覆盖,所以最终输出的是100和2。
接下来我们在使用import导入模块m。代码如下:
from m import x,y
x = 100
y[0] = 100
import m
第一次导入m时,会自动输出一条"this is m.py file"。那么现在我又导入了,是否还会输出呢?结果只输出了一次。这是因为Python解释器在执行代码时,默认只导入模块一次。后续无论导入多少次,都不会再次导入,因为导入模块会影响程序的运行效率。所以,当导入多次同一个模块时,我们只导入一次,后续的导入会被忽略。
接下来,我们再输出一下m.x和m.y,代码如下:
from m import x,y
x = 100
y[0] = 100
import m
print(m.x)
print(m.y)
输出结果:
/Users/andy/PycharmProjects/StudyPython/chapter_10/test.py
this is m-py file
1
[100,2]
运行结果m.x依然是1,m.y却变成了包含100和2的列表。原来m.y不应该是[1,2]吗?为什么此时变成了[100,2]呢?下面我们通过一个动画更好地理解。如下图所示:
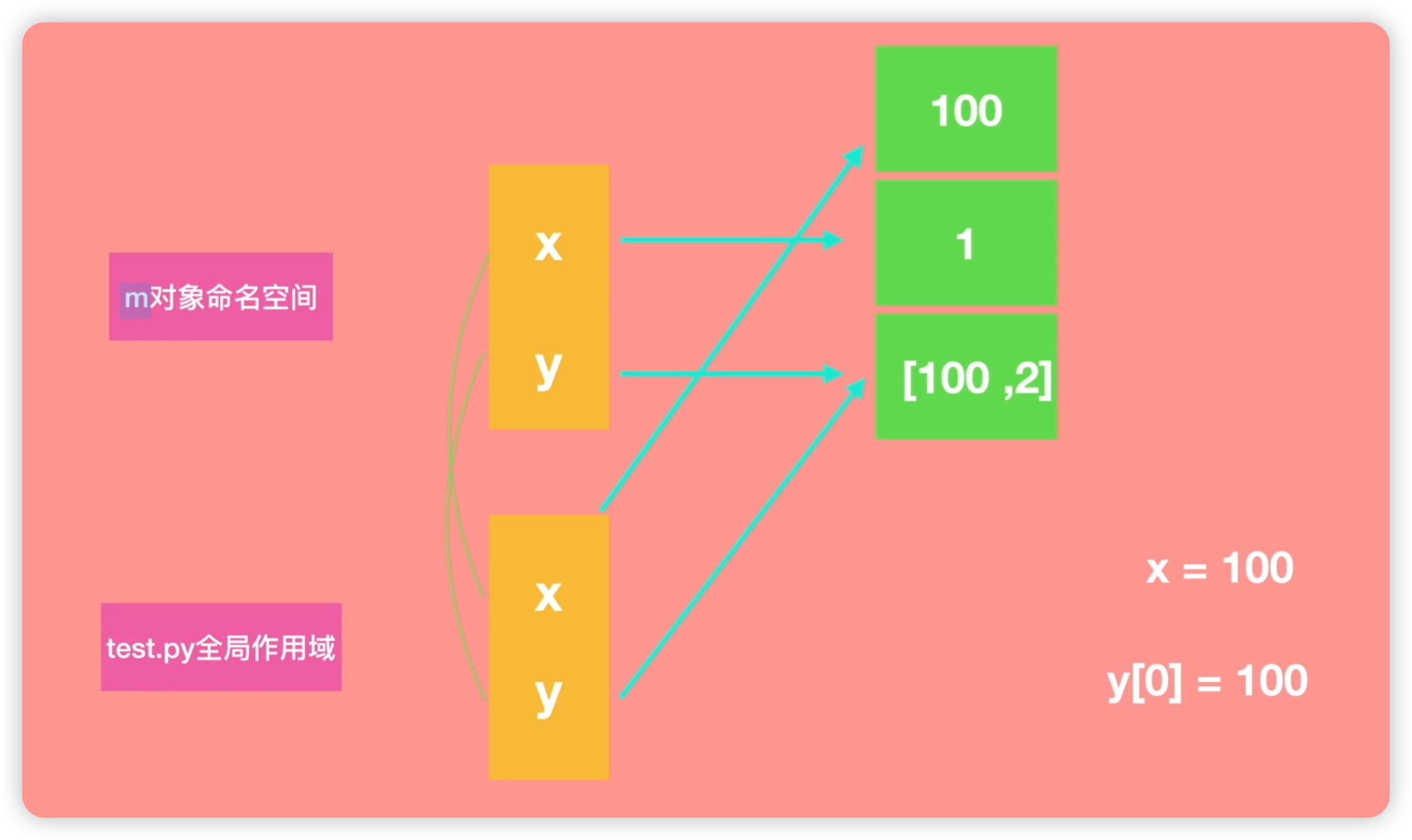
当我们导入m.py时,会创建一个m对象的命名空间。在这个命名空间中,有两个属性:x和y。x指向的值是1,y指向的值是一个列表,包含1和2。接下来我们再来看test.py的全局作用域。在这里,它也有一个x和y,这个x和y相当于将m对象中的x和y复制过来。所以它们的值也指向这里的值:x指向1,y也指向1和2这个列表,现在我们对它进行了一些操作,我们首先将变量x的值赋为100。由于x是一个不可变类型的变量,它指向的是一个数值1。当你为它赋一个新值时,实际上相当于在内存中开辟了一个新位置,将值设为100,并改变了它的指向,从1变为指向100。
接下来,我们操作了变量y,将其第一个元素赋值为100。由于y指向的是一个列表,而列表是可变类型的数据,所以修改其中一个元素并不会改变其指向地址。因此,它会在原地修改,将第一个元素改为100。这意味着变量指向的内存地址并没有发生改变。因此,当我们再次使用import导入m对象时,m.x的值依然指向1,而m.y的值已经发生了变化,从原来的1和2变成了100和2。
if __name__ == "__main__"
很多人在阅读他人代码或者编写自己的代码时,常常会在结尾处加上一个条件语句:if __name__ == '__main__'。然而,许多人却不清楚这个条件语句的作用以及为什么要使用它。本节将介绍这个神奇的if __name__ == '__main__'作用及原因。
在Python中,当我们输出一个模块时,它是一个模块对象,并且拥有一个特殊的属性叫做__name__。一个Python文件根据其作用可以分为两类:一类是可以直接执行的,比如像main.py、run.py这样的文件;另一类是被当作模块进行导入的,比如function.py。对于后者,虽然可以导入,但执行它并不会产生任何输出,因为它主要是函数或者其他可导入的对象。如下图所示:
然而,有时我们需要检验这些函数能否正常运行,如果在调用它的文件中再次导入,会显得有些麻烦。在编写代码时,可以使用条件语句 if __name__ == '__main__',在其中编写特定的逻辑。这个条件语句的作用是检测当前模块是否作为主模块直接执行。在Python中,每个模块都有一个特殊的属性 __name__,用于标识模块的名称。编写代码如下:
# 定义一个函数,用于计算两个数的和
def add(x, y):
return x + y
# 定义一个函数,用于计算两个数的差
def subtraction(x, y):
return x - y
# 如果当前模块是主模块(即直接执行的模块),则执行以下代码块
if __name__ == "__main__":
# 输出当前模块的名称
print(__name__)
输出结果:
__main__
我们可以通过输出 __name__ 属性的值来确认当前模块的名称。在直接执行的情况下,__name__ 的值会是 '__main__',因此条件语句会被执行。接着,我们可以在这个条件语句下编写测试代码,例如调用一些函数并输出结果,以确保它们的正常运行。代码如下:
# 定义一个函数,用于计算两个数的和
def add(x, y):
return x + y
# 定义一个函数,用于计算两个数的差
def subtraction(x, y):
return x - y
# 如果当前模块是主模块(即直接执行的模块),则执行以下代码块
if __name__ == "__main__":
# 输出当前模块的名称
print(__name__)
# 调用subtraction函数,并输出结果
print(subtraction(1, 2))
输出结果:
__main__
-1
当我们在模块中编写了一些测试代码时,其他调用该模块的文件不会受到影响。以 test.py 为例,代码如下:
import utils.function
print(utils.function.add(100,200))
输出结果:
300
即使导入了function模块,function模块其中的代码也不会执行,因为function模块中的 __name__ 的值并非 '__main__'。这可以通过在 test.py 中输出 __name__ 属性的值来确认。代码如下:
# 导入名为utils.function的模块,并给其取别名为function
import utils.function as function
# 调用function模块中的add函数,并输出结果
print(utils.function.add(100, 200))
# 输出function模块的所有属性和方法列表
print(dir(function))
# 输出function模块的名称属性
print(function.__name__)
# 输出当前模块的名称
print(__name__)
输出结果如下图所示:

通过给模块添加 if __name__ == '__main__' 条件语句,我们可以确保在模块被直接执行时执行特定的代码,而在被其他模块导入时不执行。这种做法使得每个模块都能够独立运行和测试,为项目的模块化开发提供了便利。
因此,在开发过程中,我们通常会将项目进行模块化,即拆分成多个文件。为了保证每个文件都能正常运行,我们可以在每个模块中使用 if __name__ == '__main__' 条件语句进行单独测试。如果出现问题,可以单独修改某个模块,而不影响其他模块的正常运行。最终,在整个项目测试通过后,我们就可以放心地将其部署和使用。
常用内置模块random
本节将介绍random模块。在之前的学习中,我们已经广泛使用了random模块来生成随机数。在介绍它之前,让我们先查看一下它的文档。在Python标准库中,我们可以通过搜索来找到random模块。如果你是Windows用户,可以按下CTRL+f;而如果你是Mac用户,则按下command+f。这将弹出一个搜索栏,在其中输入"random",我们就可以定位到random模块的位置。
我们点击random模块进入其文档页面。在这个页面中,我们可以查看random模块的文档,也可以查看其源代码。我们本节介绍random模块比较常用的5个方法。如下图:

首先是random.random方法,它用于生成一个0到1之间的随机浮点数。
第二个是random模块的randint方法,根据名称中的"int",我们可以了解到它用于生成一个指定范围内的整数。范围包括起始值和结束值,比如如果设置起始值为1,结束值为10,那么将生成1到10之间的整数,包括1和10在内。
第三个是random模块的randrange方法,它类似于range函数,接受起始值、结束值和步长作为参数。通过设置步长,我们可以生成指定步长的整数序列,比如设置步长为2,就会生成从1到10之间的所有奇数。
第四个是random模块的choice方法,它用于在序列中随机选择一个元素。这个序列可以是字符串、列表或元组。
第五个是random模块的shuffle方法,它用于随机打乱列表的顺序。这个方法只能用于列表,因为它会改变原列表的顺序。对于字典而言,因为字典是无序的,所以打乱顺序没有意义,shuffle方法也不能用于字典。需要注意的是,使用shuffle方法后,原列表会被改变。
下面我们将在代码中演示random模块的常用方法。我们将在其中创建一个名为"random_function.py"的文件。现在,让我们导入random模块,使用"import random"即可。之后,我们可以直接调用random模块的方法。我们首先看一下random.random方法,代码如下:
# 引入random模块
import random
# 使用random模块的random方法生成一个0到1之间的随机浮点数,并打印输出
print(random.random())
输出结果:
0.574470058075571
运行后可以看到结果是一个范围在0和1之间的浮点数。如果觉得每次调用都需要使用"random."较为繁琐,我们可以修改一下,使用"from random import"��的形式。这样我们就可以直接调用random方法了,代码如下:
# 从random模块中导入random方法
from random import random
# 使用导入的random方法生成一个0到1之间的随机浮点数,并打印输出
print(random())
运行后可以看到结果的浮点数已经发生了变化。这就是random方法,它可以用来随机生成一个0到1之间的浮点数。
接下来我们来讨论第2个方法,即生成整数的randint函数。首先,我们需要区分一下它与之前学习的range函数的不同之处。在使用randint时,我们要注意它会包含指定范围的左右边界值。我们来演示一下,直接调用randint方法,代码如下:
from random import random, randint
# 随机生成一个start,stop之间的整数,包含右侧的值
print(randint(1,3)) # range(1,3) 它是不包含右侧的值
需要注意的是,与range函数不同,如果是1到3的范围,range函数是不包含右边界值的,而randint函数则包含右边界值。
接下来我们来看一下randrange函数,代码如下:
from random import random, randint, randrange
# 随机生成一个start,stop之间的整数,默认步长是1
# 如果设置步长为3,从1,1+3,1+3+3,以此类推,不包含右值
print(randrange(1,10,3)) # randrange() 与range()类似,它是不包含右侧的值
如果我们将步长改为3,生成的值就是1、4、7中的一个值,因为下一个值11超出了范围,所以只能取这三个值。我们可以多次运行来验证,结果始终在这三个值之间变化。总结一下,randrange函数用于随机生成指定范围内的整数,默认步长是1,并且不包含右边界值。
接下来我们来学习另一个choice方法。该函数用于从序列中随机选择一个元素。这个序列可以是字符串、元组或列表。使用choice函数进行测试。代码如下:
from random import random, randint , randrange, choice
# 从字符串,列表,元组中随机选择一个元素,不能随机选择字典和集合的元素
string = 'hello world'
tuple_value = (1,2,3,4,5)
list_value = [1,2,3,4,5]
dict_value = {"name":"andy","age":18}
set_value = {1,2,3,4,5}
print(choice(string))
print(choice(tuple_value))
print(choice(list_value))
接着我们来看最后一个shuffle方法,shuffle函数用于随机地改变一个序列的顺序。然而,它要求序列是可变类型,而字符串和元组是不可变类型,所以它们不能使用shuffle函数。我��们尝试了使用一个字符串和元组进行测试,但由于字符串和元组是不可变的,所以报错了。接下来我们使用了一个可变类型,即列表list_value,运行后没有报错。代码如下:
from random import random, randint , randrange, choice,shuffle
# 列表可以使用shuffle,更改原来列表的顺序
string = 'hello world'
tuple_value = (1,2,3,4,5)
list_value = [1,2,3,4,5]
dict_value = {"name":"andy","age":18}
set_value = {1,2,3,4,5}
shuffle(list_value)
print(list_value)
输出结果:
[4, 3, 1, 5, 2]
需要注意的是,shuffle函数不会输出结果,因为它是直接更改了原列表的顺序。我们再次运行后,发现列表的顺序发生了变化。但是对于字典来说,它是无序的,所以无法使用shuffle函数。我们尝试了使用一个字典dict_value进行测试,同样报错了。最后我们尝试了使用集合,同样会报错。这说明只有列表才能使用shuffle函数,它可以用来改变原列表的顺序。
日期时间模块的基本概念
在今后的项目开发中,我们经常需要处理日期和时间相关的任务。比如,后台系统可能需要记录管理员或用户的登录时间,而商城系统可能需要记录用户下单、交易和发货的时间等。为了处理这些任务,Python提供了一些日期和时间相关的模块。在深入讨论这些模块之前,我们需要先理清几个概念。
首先是GMT(格林威治标准时间),也被称为格林尼治时间。格林尼治时间以英国伦敦郊区的皇家格林威治天文台为基准,在那里,每天太阳经过的时间被标记为中午12:00。虽然GMT是一个较旧的时间计量标准,但由于地球自转速度的变化,它不再是一个精确的标准。后来,人们开始使用UTC(协调世界时间),它基于原子钟计算时间,精度非常高,误差只有50亿年才会达到一秒。因此,现在我们通常使用UTC作为世界标准时间。另外,本地时间(LT)指的是各个地方的当地时间,比如北京时间、美国时间、伦敦时间和日本时间等。GMT、UTC和LT之间的关系是:通常情况下我们认为GMT和UTC是相等的,而本地时间则是根据UTC时间再加上一个时区差来换算的。
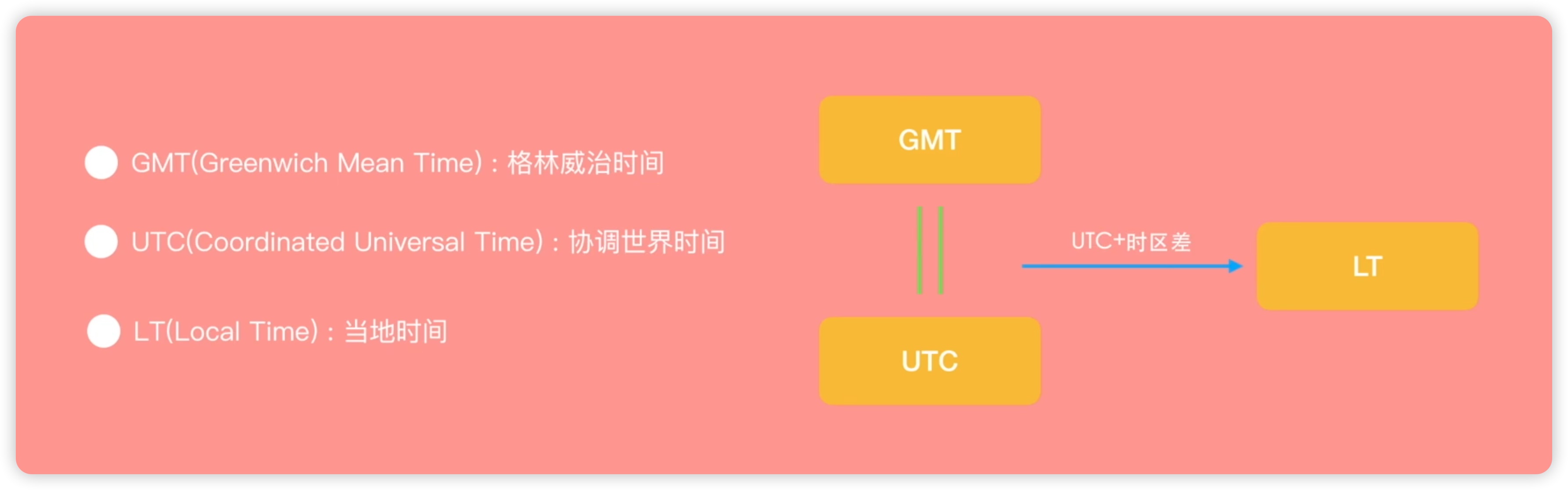
现在我们来对比一下UTC时间和我们的北京时间,我把格林威治时间设置为零点,格林威治时间早上的凌晨,就是我们北京时间的8:00 如下图所示:
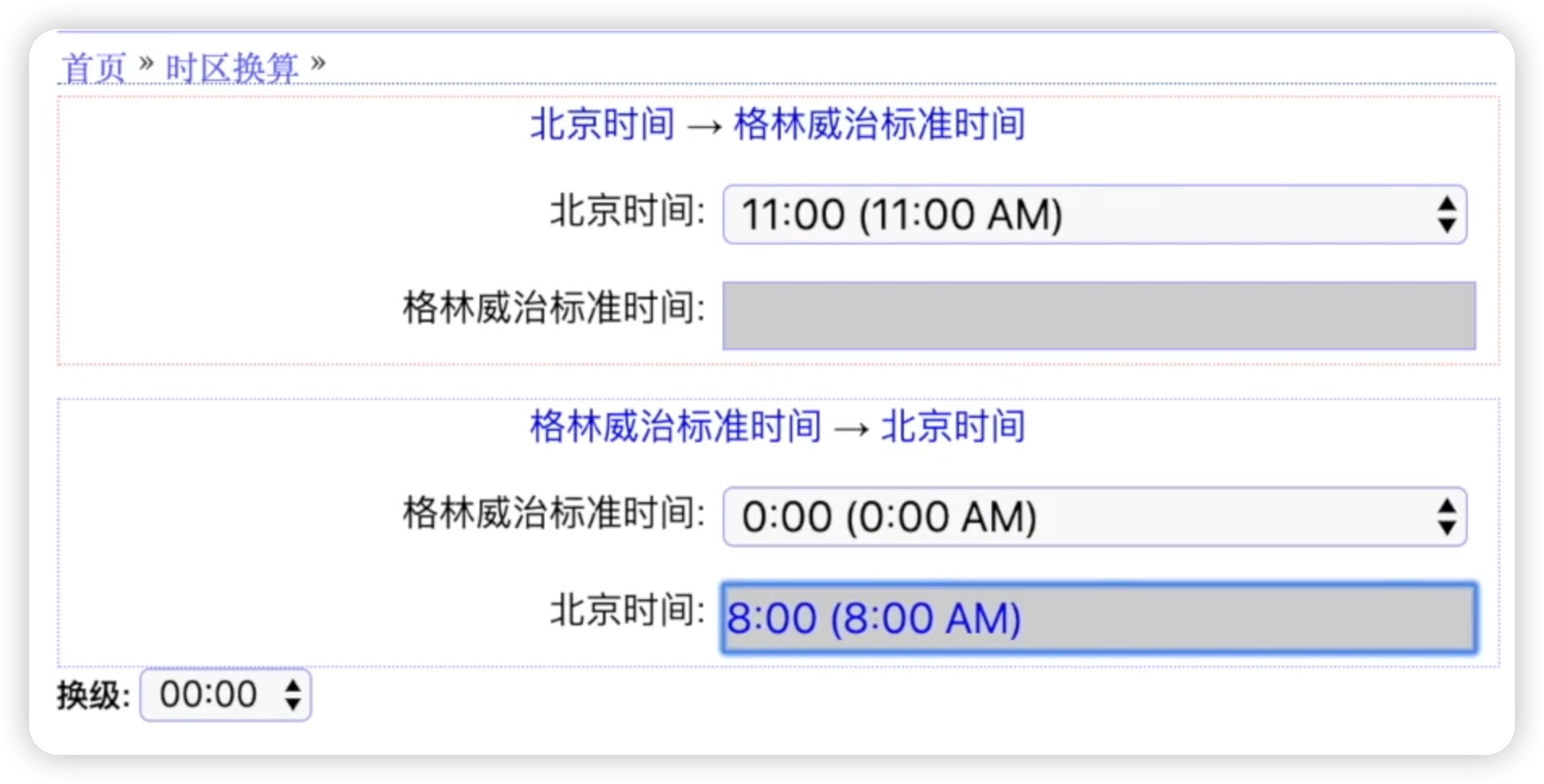
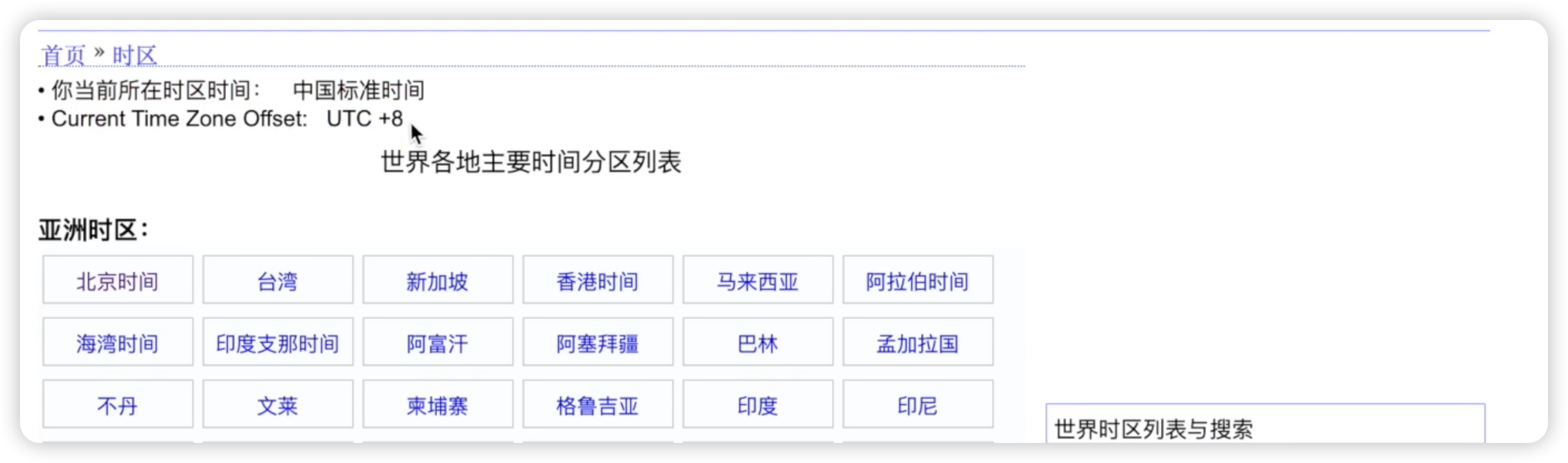
这是因为我们在北京地区的时间,它有8个小时的时差,也就是时区是+8的,我们可以看一下这个时区,世界时间时区,看到您当前所在的时区是中国标准时间,本地的时间应该是UTC+8,也就是我们的时区是+8,如下图所示:
这就是GMT、UTC与LT它们之间的关系
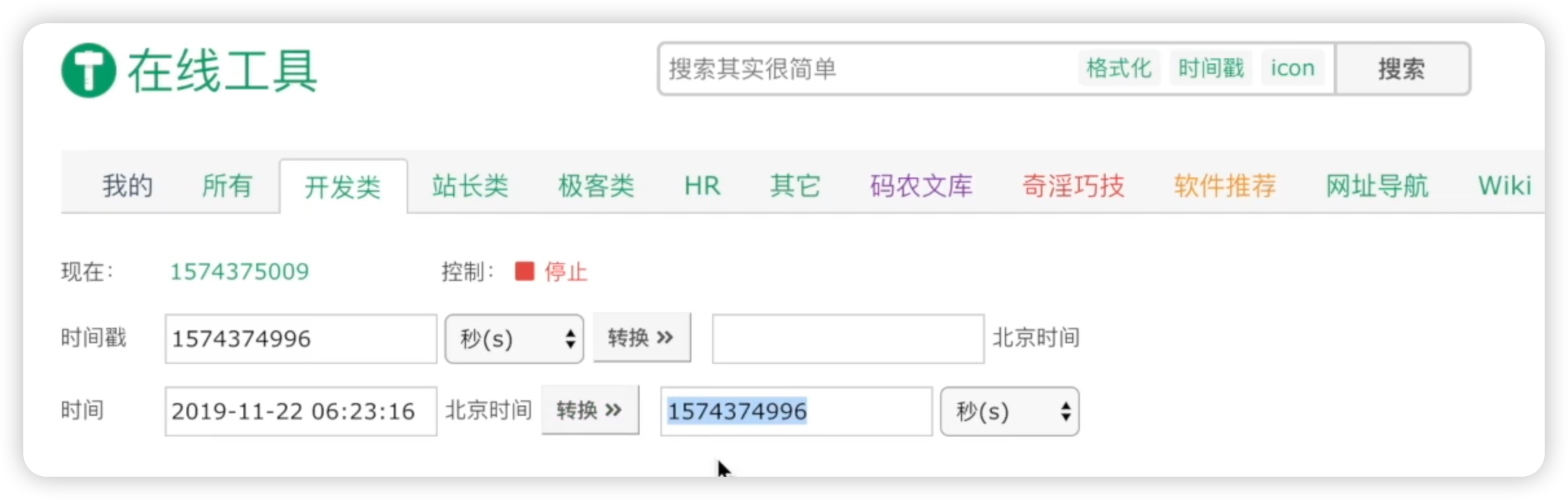
另一个概念是时间戳或Unix时间戳,它指的是从1970年1月1日凌晨开始,到现在所经历的秒数。我们也可以查看一下时间戳工具:在线时间戳,我们把当前的时间转化为时间戳,点击转换按钮,转换按钮后面的数字就是时间戳,如下图所示:
它是如何计算的呢?Unix时间戳之所以选择1970年1月1日作为起始时间,是因为Unix操作系统最早在1969年发布,而在1970年底出版了一个叫Unix编程手册的书籍,里面定义了从1971年1月1日开始的时间。后来,由于1971年不太好计算,就改成了从1970年1月1日开始。需要注意的是,Unix时间戳主要用于记录计算机系统的时间,在1970年之前的时间可以用负数表示。另外,由于早期的Unix系统是32位操作系统,时间戳有一个范围限制,导致了2038年问题。如果系统仍然是32位操作系统,到了2038年,时间戳会发生溢出,导致系统时间混乱,很多软件可能无法正常运行。不过,大多数现代操作系统都是64位的,因此不会受到这个问题的影响。

常用内置模块time
以下是Python中常用的日期时间模块:time模块,其次是datetime模块,再接着是calendar模块。我们先来学习一下time模块。
在我们初中学习物理知识时,曾介绍过三种物质的转换形态,比如水,它可以存在液体、气态和固态。如下图所示:
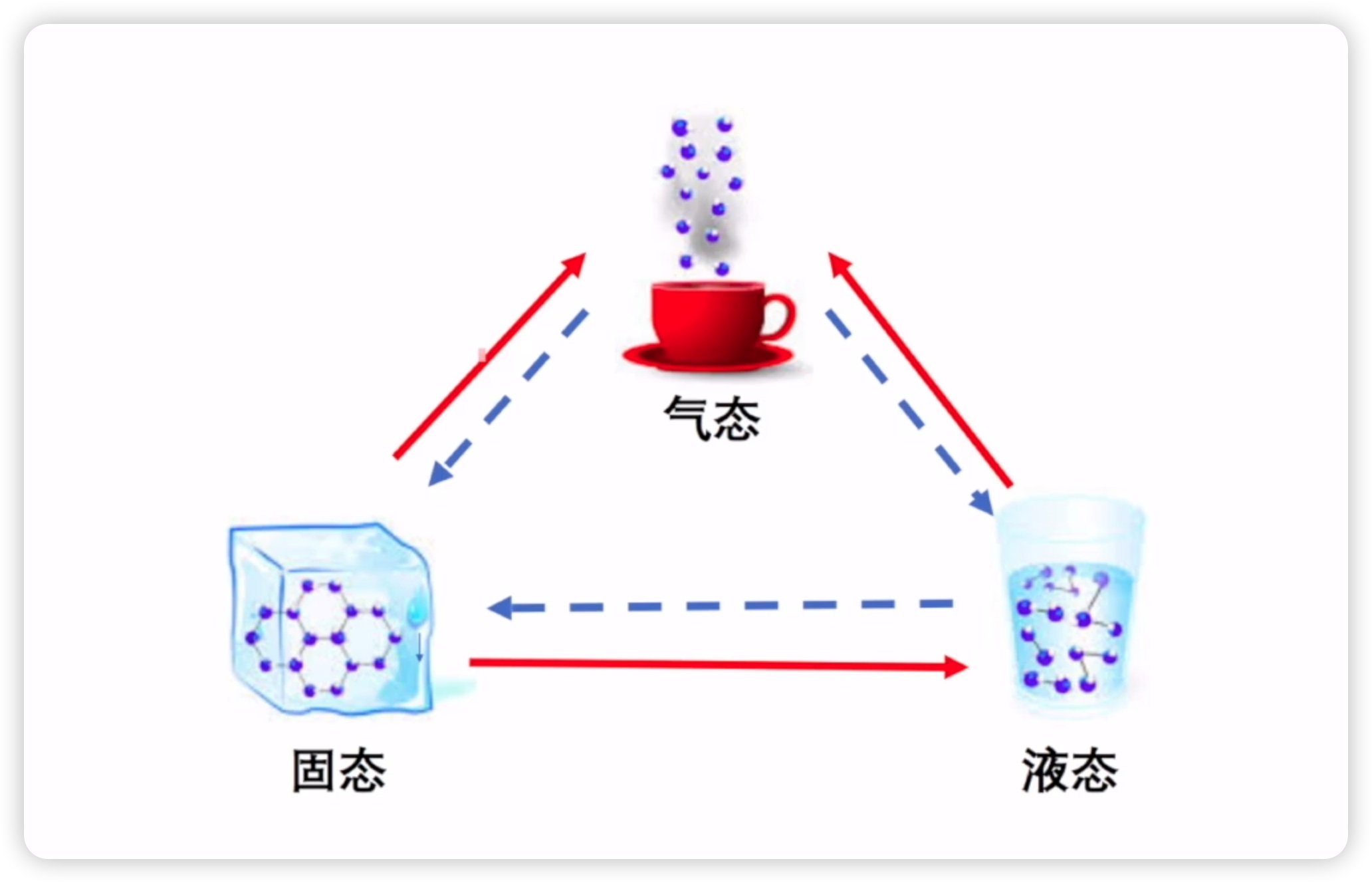
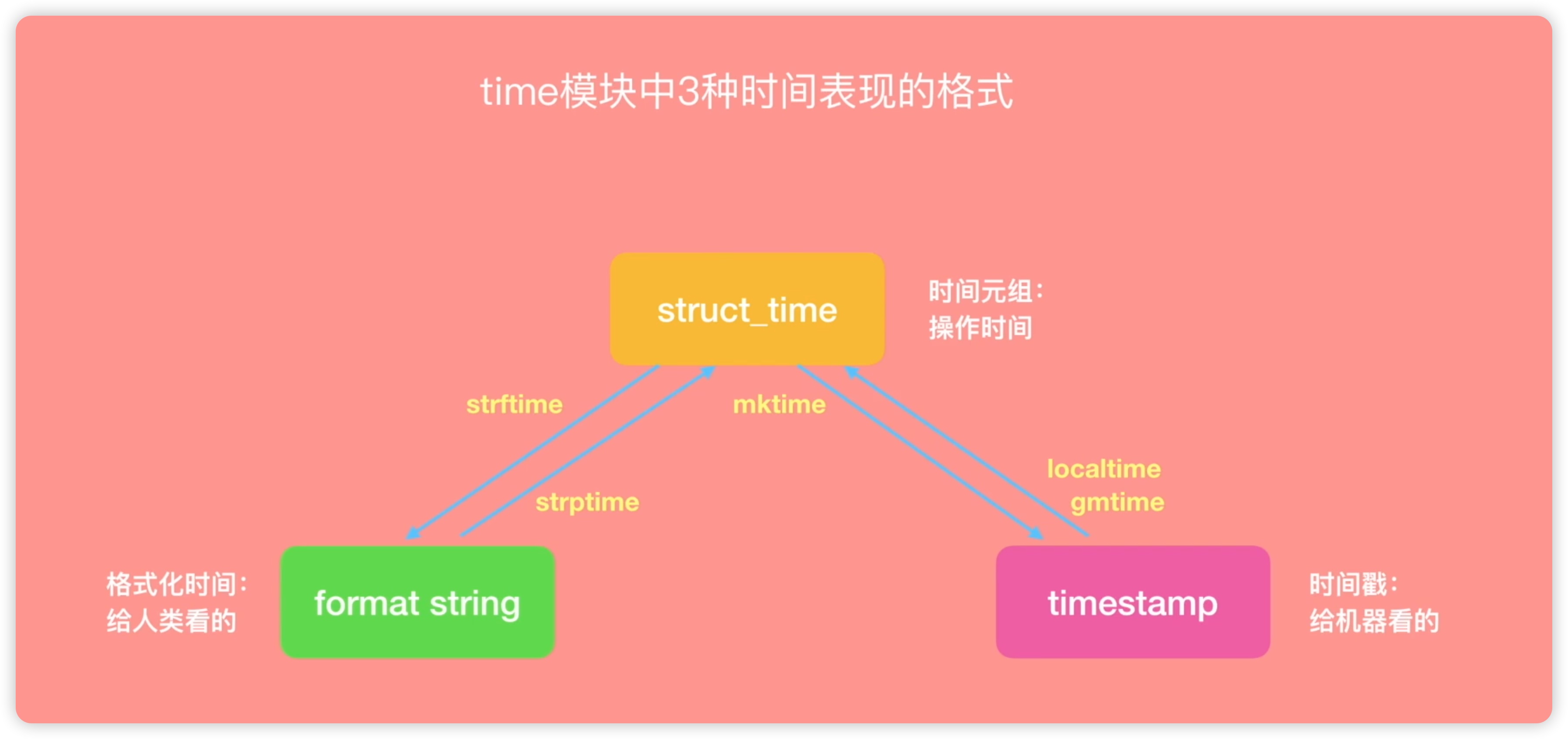
在time模块中,同样存在三种时间表现格式,分别是struct_time、时间元组和timestamp,以及format string格式化时间。那么,这三种时间表现形式各自有何用途呢?如下所示:
首先,让我们来介绍timestamp时间戳。时间戳是从1970年1月1日开始计算,表示从那一刻起到现在的总秒数。它的作用主要是为机器提供时间信息。我们先来感受一下这个timestamp,也就是时间戳。在打开idle后,我们可以通过导入时间模块(import time)来生成一个时间戳,使用time.time()方法即可。如下图所示:
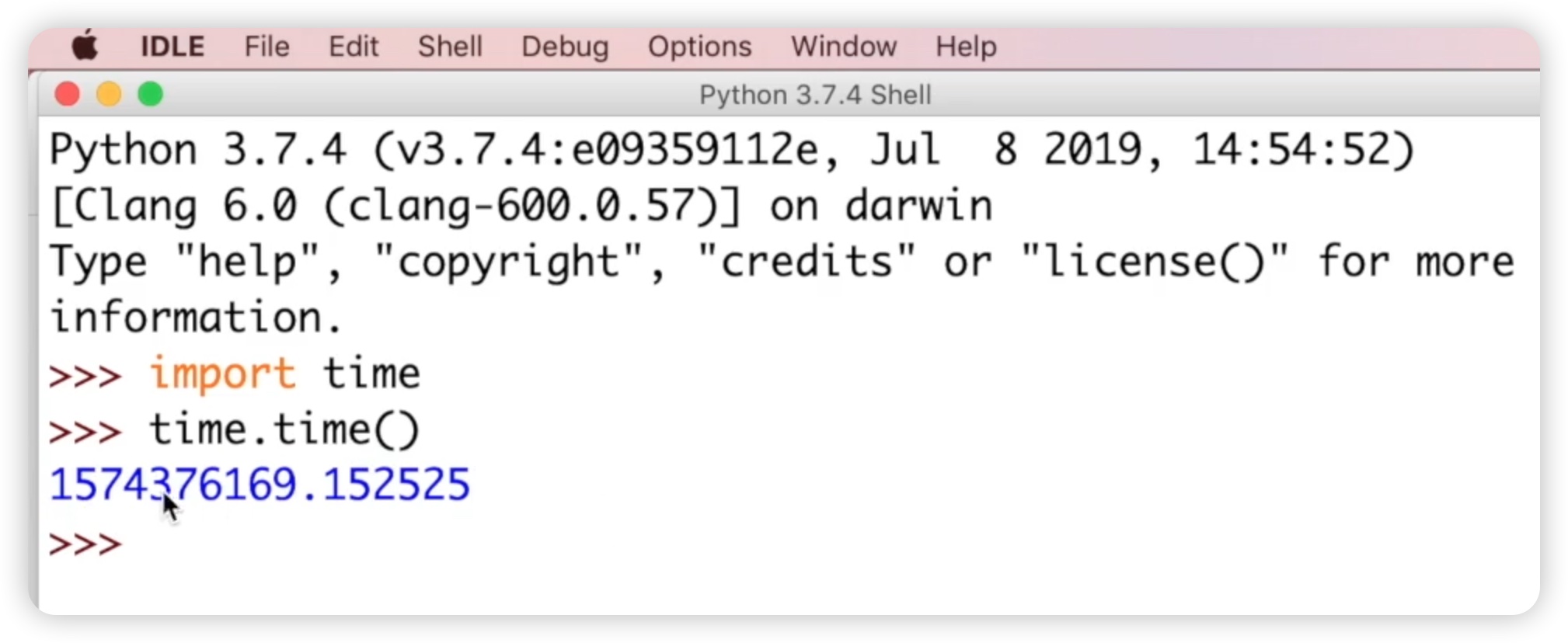
返回的结果是一个浮点数,因为它非常精确。通常情况下,我们会取整数部分,这样就得到了从当前时间到1970年1月1日凌晨开始的时间戳。
接下来,让我们来了解一下struct_time。它是一个时间元组。我们可以将时间戳转换为时间元组,可�以使用两个方法,一个是localtime,另一个是gmtime。现在我们定义一个名为timestamp的变量,它代表时间戳,等于time.time()。看一下timestamp,如下图所示:
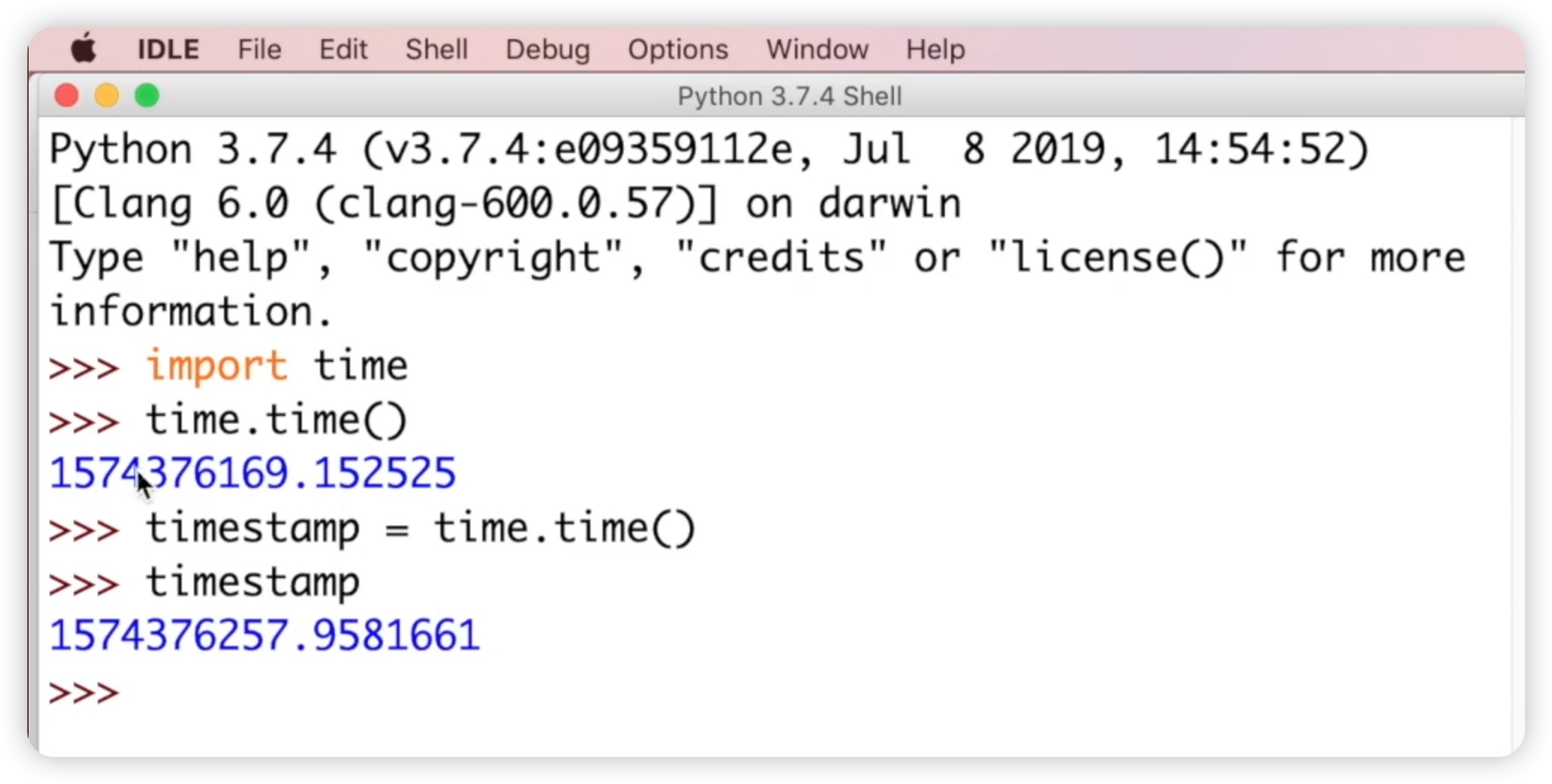
小伙伴们会发现这个秒数已经发生了变化,因为刚才的时间和当前时间是不同的。然后我们调用函数time.gmtime。gm代表格林威治时间,gmtime表示将当前时间戳转换为一个时间元组。如下图所示:
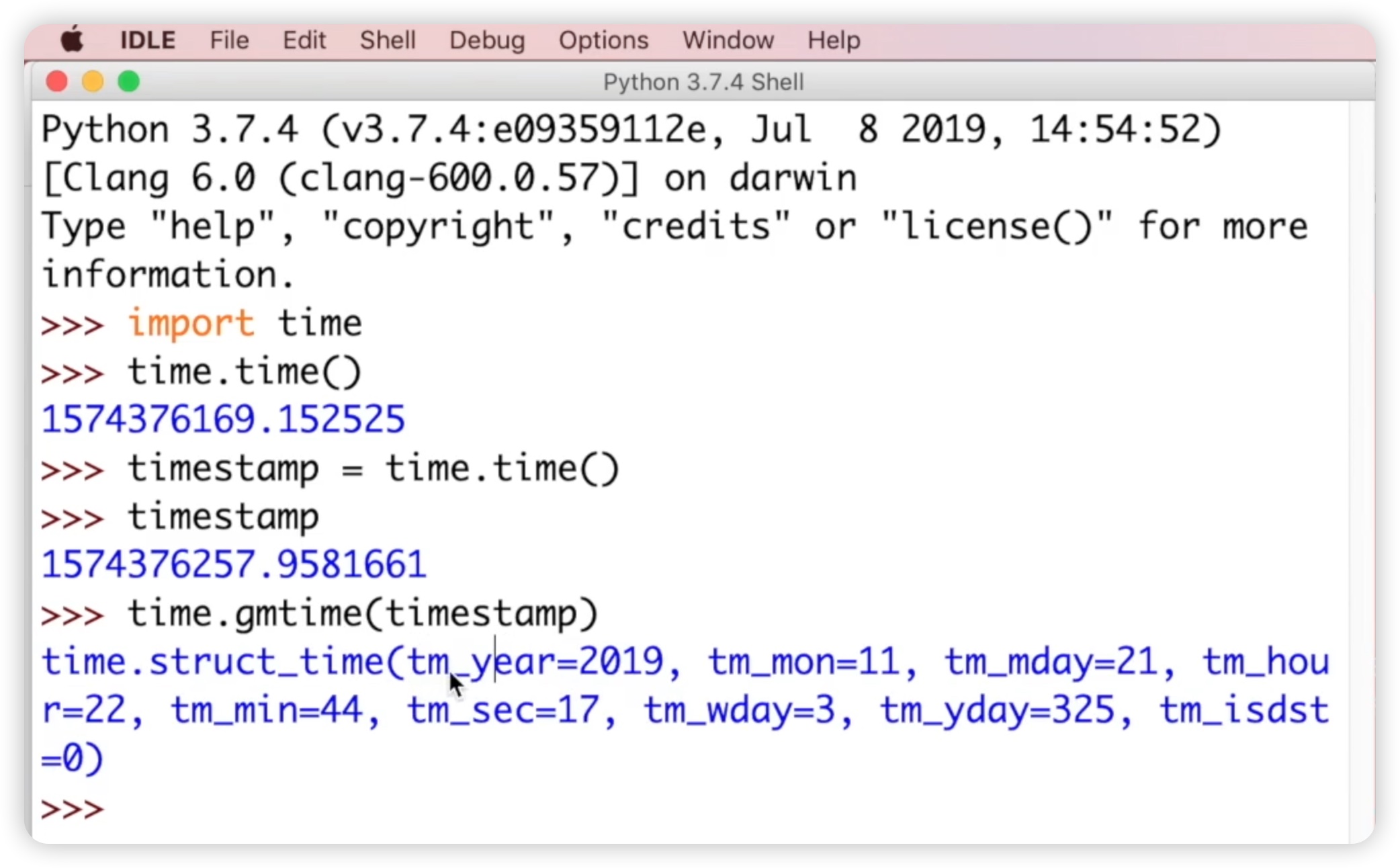
最终输出的结果是一个time.struct_time时间结构,其中包含很多参数,如tm_year表示年份(当前是2019年)、tm_mon表示月份(11月)、tm_mday表示日期(21号,但我们当前是22号,因为使用的是格林威治时间)、hour表示小时(6点)、minute表示分钟(44分)、second表示秒数(17秒)、wday表示星期(从零开始,3表示星期四)、yday表示在一年中的第多少天(当前是第325天)、isdst表示夏令时标志。在中国我们通常忽略这个标志。这样,我们就将时间戳转换为时间元组。之所以称其为时间元组,是因为它像元组一样有多个参数,一共有9个参数。
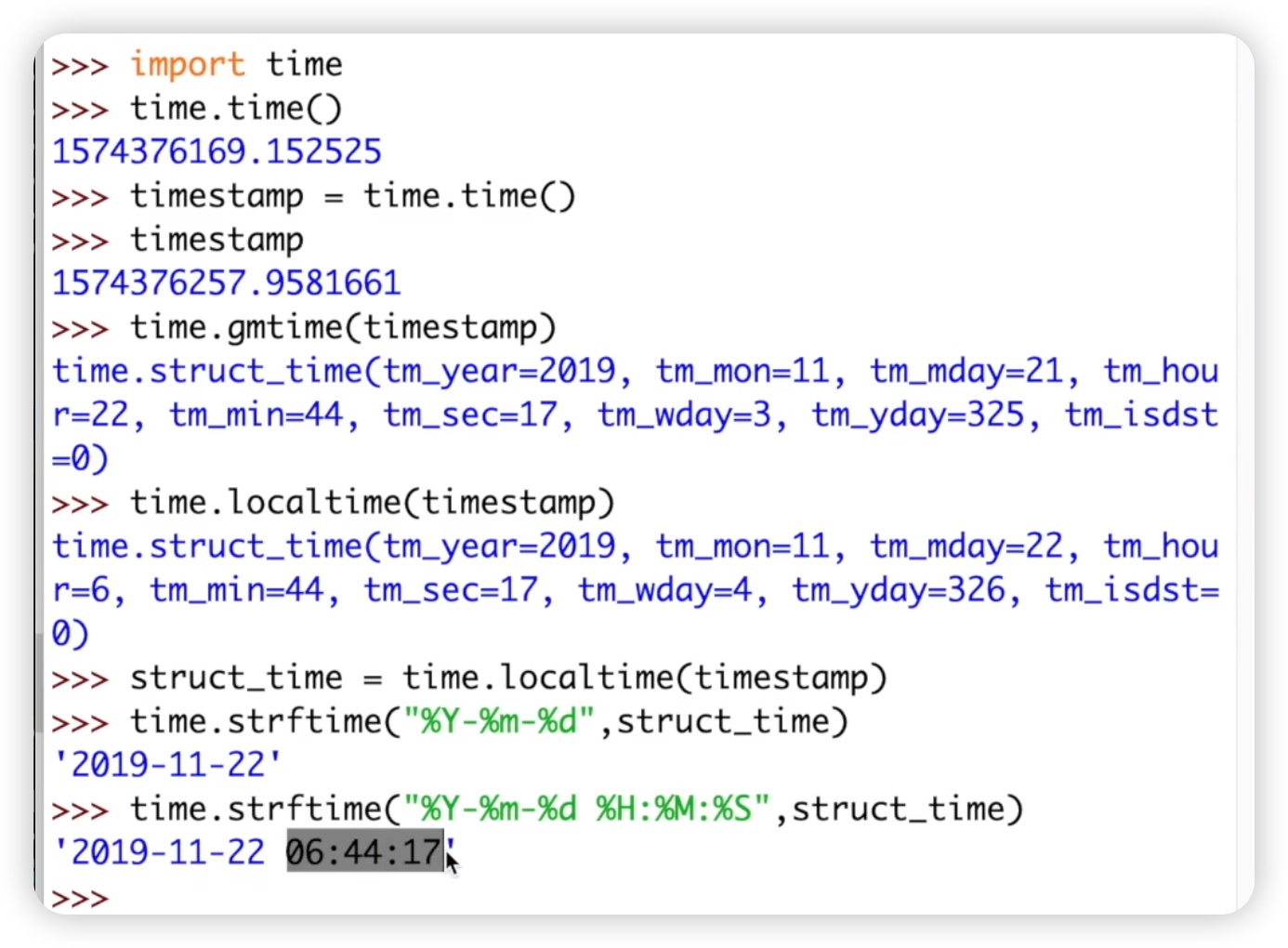
接着我们来看format string的用途,它是为了人类方便阅读。因为单纯看时间戳的数字,我们无法猜出对应的日期。而时间元组主要用于计算,对于人类来说不够方便。因此我们需要一种格式化的方式,让人类更容易阅读。这就是时间格式化,也就是format string。我们可以将时间元组转换为format string,使用strftime方法。我们给它传递一个名为struct_time的变量,然后使用time.strftime()传递一个参数,即struct_time。strftime中有两个参数,第一个参数是我们要设置的格式化方式,因为不同文化习惯的不同,我们可以根据自己的喜好设置时间格式。比如我们可以使用“年-月-日”的格式。这样,我们就将原来的格式化时间转换为一个便于我们阅读的年月日的形式。如下图所示:

我们还可以设置年月日时分秒。一般来说,我们会以一定格式来表示时间,例如年月日之间加上空格,然后用时分秒来表示,使用冒号来分隔。代码如下:

运行代码后,我们可以看到时间被以这种格式呈现出来。需要注意的是,我在这个格式中添加了一些符号,比如杠和百分号,这是为了让格式看起来更加美观。当然,根据个人习惯,你也可以自行设置这些符号的样式,但通常约定俗成的格式是年月日之间使用杠,时分秒之间使用冒号。你也可以将年月日改成斜杠的形式,再进行设置。
除了这三种时间表现格式能够相互转换外,它们还可以转化为时间字符串。如下图所示:
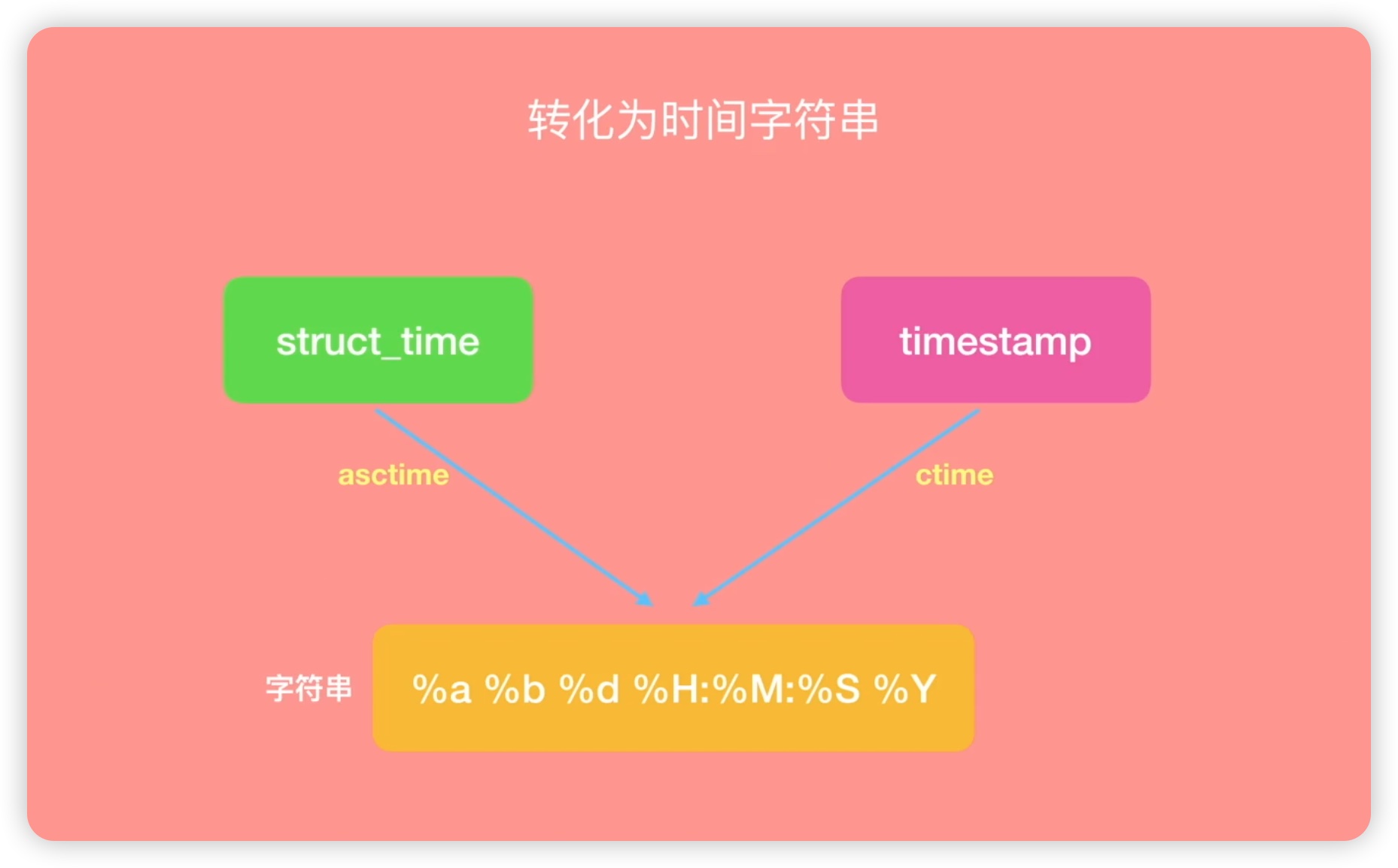
时间字符串的形式包括了年、月、日、时、分、秒等元素,我们可以根据自己的需要进行设置。为了方便记忆,我还为大家提供了这些函数的单词缩写,比如ctime��代表char time,即字符串时间;asctime代表ASCII码的时间格式。每个函数都有其特定的作用,例如strftime用于格式化时间字符串,而strptime则用于解析时间字符串为时间元组。最后一个函数mktime则用于将时间元组转换为时间戳。现在,我们对time模块有了一个大致的了解,但如果需要更多函数的具体用法,我们仍需查阅官方文档。
常用内置模块datetime
在本节中我们将介绍另一个与时间相关的模块,名为datetime模块。从这个名称中,大家可能已经猜到,它与日期和时间相关。让我们来看一下datetime模块。我们来查看Python标准库中datetime模块的介绍。在这个模块中,有一个重要的数据类型叫做datetime,它是基本的日期和时间类型。在这个模块下包含了许多内容,我们看一下左侧的分类,这个文档非常详尽。如下图所示:
在本节中,我们将对这些内容进行整理和归纳。在datetime模块中,有许多类,如下图所示:
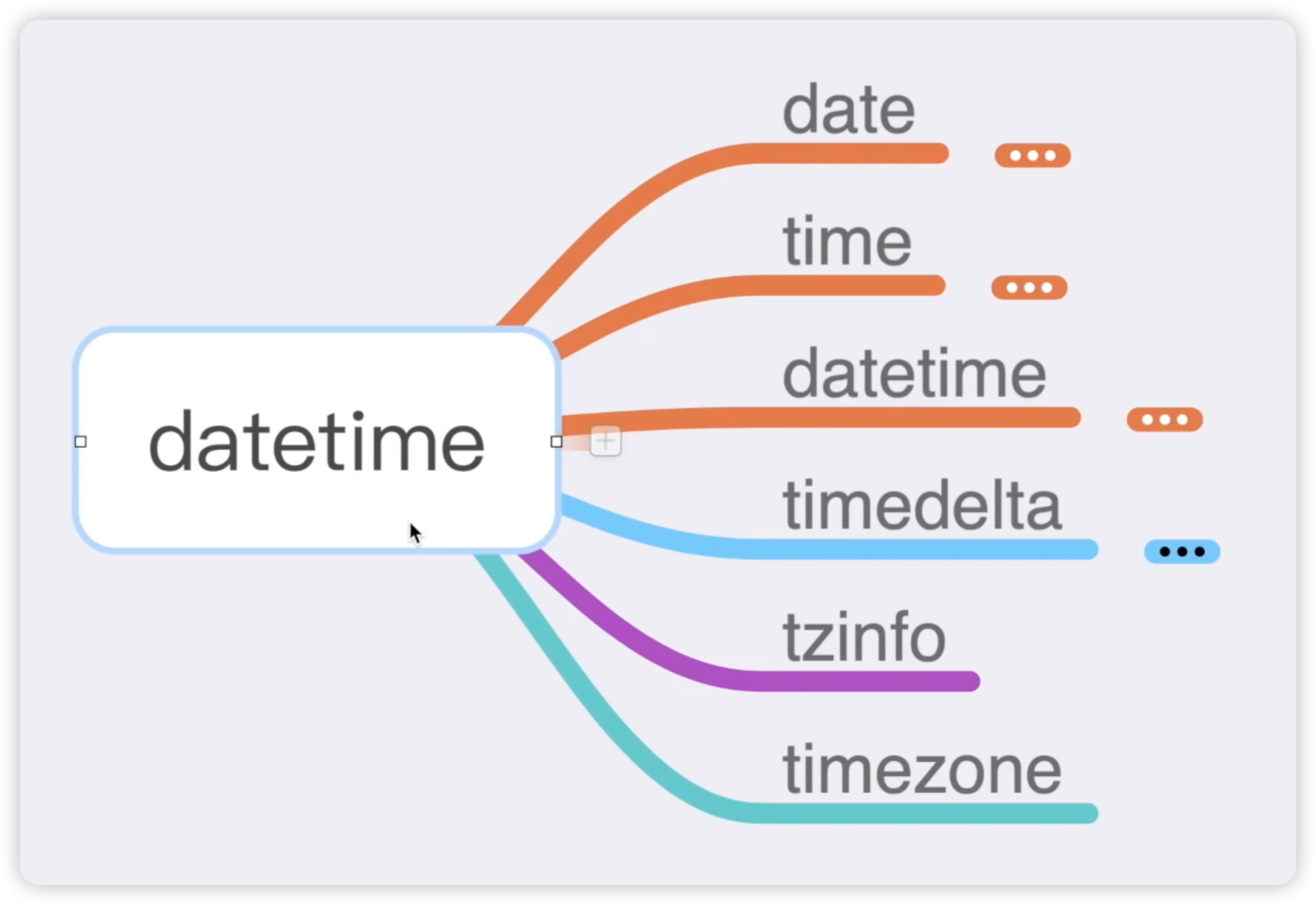
比如date类,它是一个日期对象;time类,它是一个时间对象;datetime类,它是日期和时间的综合;timedelta类,它是一个时间间隔的对象;tzinfo类,它是一个时区信息相关的对象;最后一个是timezone类,它是对时区信息的一个补充。既然这些都是对象��,那么它们就有相应的属性和方法。
- date
现在,让我们来看date对象具有哪些属性和方法。如下图所示:
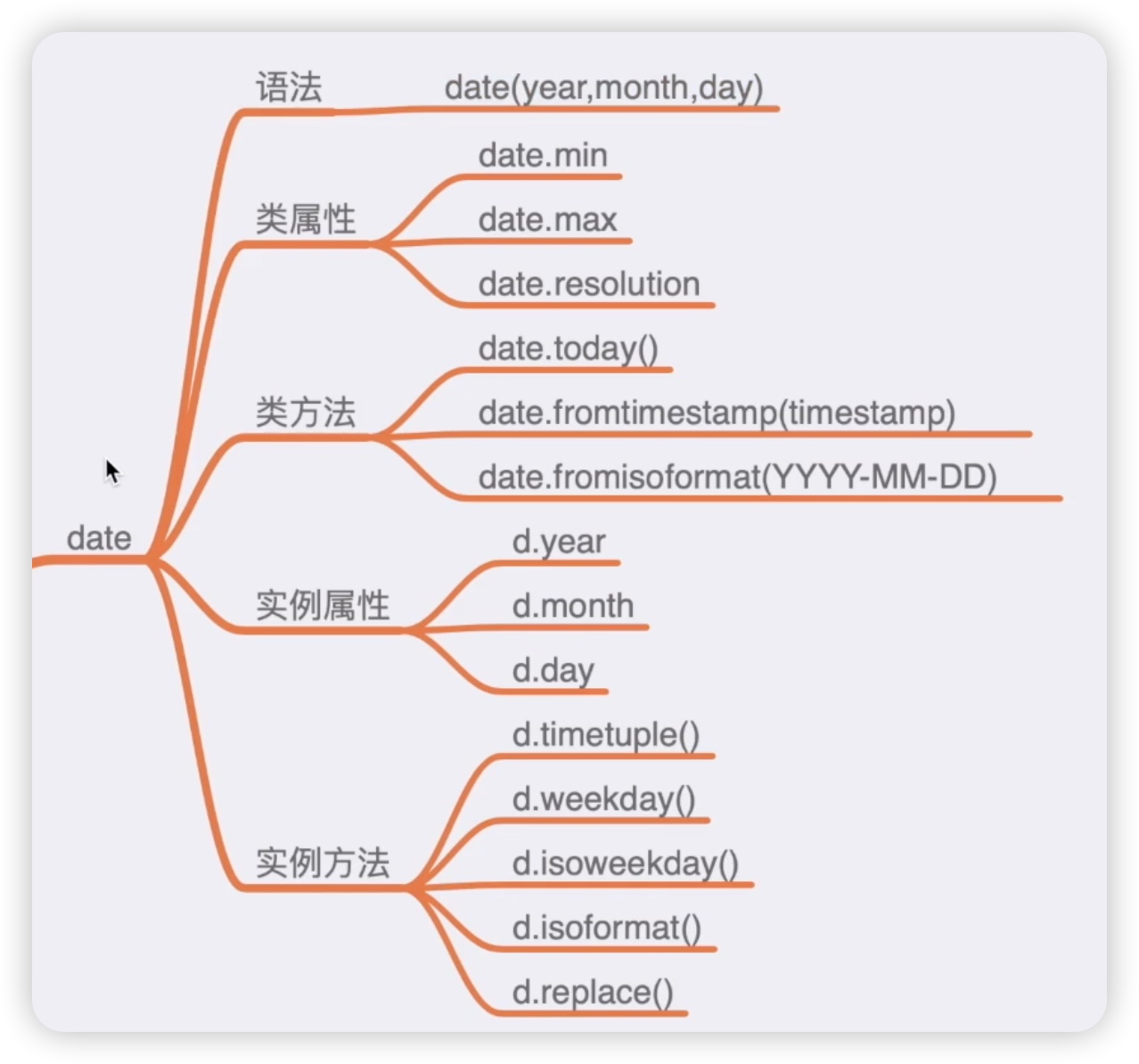
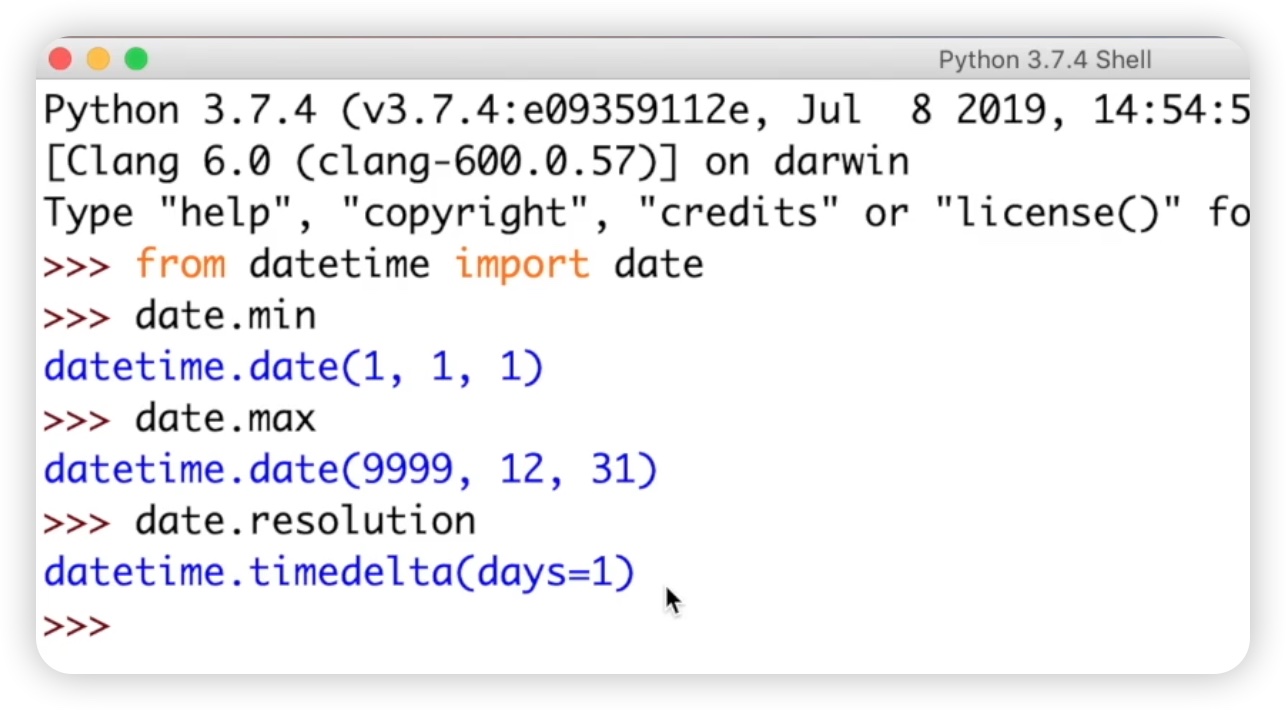
它的语法格式是需要包含三个参数,即年、月和日。接下来,我们来讲解类属性和类方法。对于类属性,我们可以直接使用类名称来调用。例如,date.min表示日期的最小值,date.max表示日期的最大值,date.resolution表示两个日期对象的最小间隔。然后,我们来演示一下,我们直接在IDLE中导入datetime模块,并调用对象的类属性。date.min返回的是一个datetime类型的数据,它的最小值是1年1月1日。类似地,date.max最多能表示的日期是9999年12月31日。date.resolution返回的是一个timedelta类型的数据,表示两个日期对象的间隔以天为单位。代码如下图:
首先,我们需要创建一个日期函数,例如d1表示某个具体的日期,使用date函数来表示,年月日分别对应着不同的参数。类似地,我们创建了另一个日期对象d2,同样使用date函数。然后,我们对这两个日期对象进行相减操作,即d2减去d1,代码如下图:
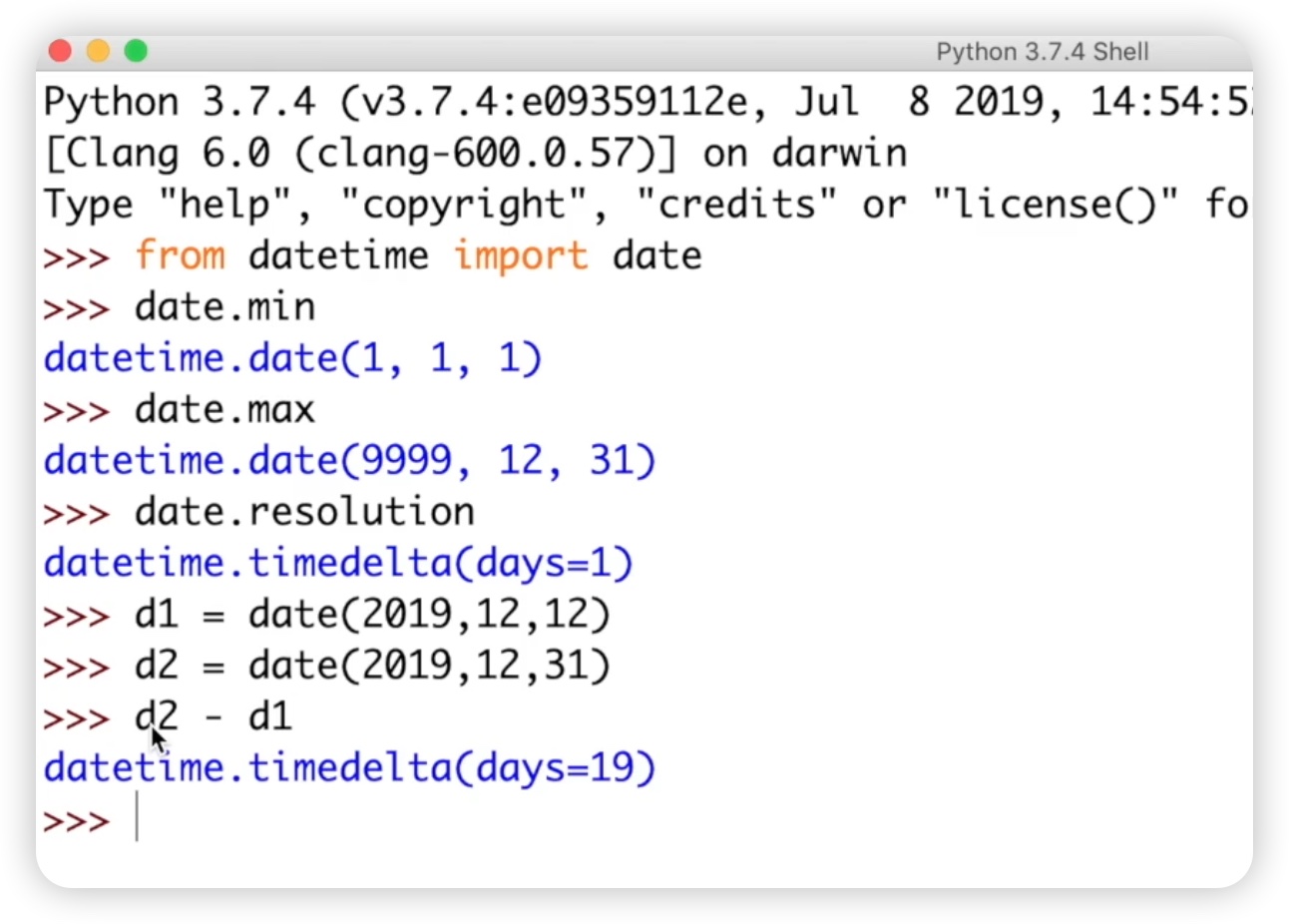
以观察返回的结果。这个结果是一个timedelta类型的对象,其中的days属性表示这两个日期相隔的天数,这里是19天。另外,date.resolution属性告诉我们,两个日期相减后的单位是天数。
接下来,我们来看类方法。类方法可以直接调用,比如date.today()方法可以获取当前日期。需要注意的是,方法名后面有括号,因为它是一个方法。另一个方法是date.fromtimestamp,它可以将时间戳转化为当前的日期。我们首先需要传递一个时间戳作为参数,可以使用time模块来获取时间戳,然后调用date.fromtimestamp方法来将时间戳转换为日期格式。代码如下图:

然后,我们来讨论实例属性。实例属性需要先将类进行实例化,前面我们已经实例化了两个日期对象。现在,我们可以调用实例的属性,比如d.year获取年份,d.month获取月份,d.day获取日期。这样就可以获取到年月日的信息了。代码如下图:
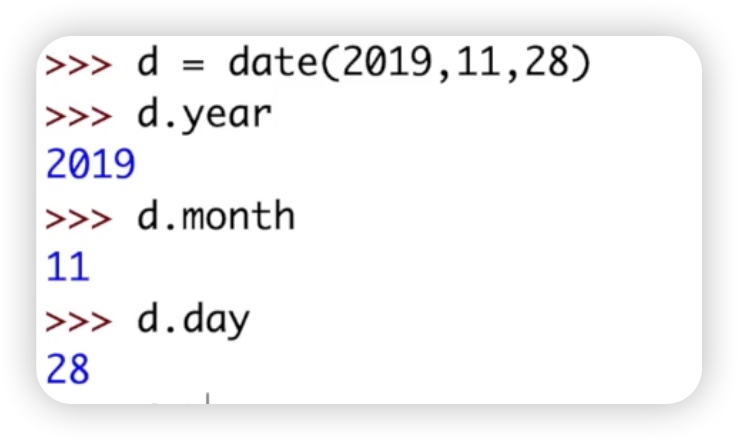
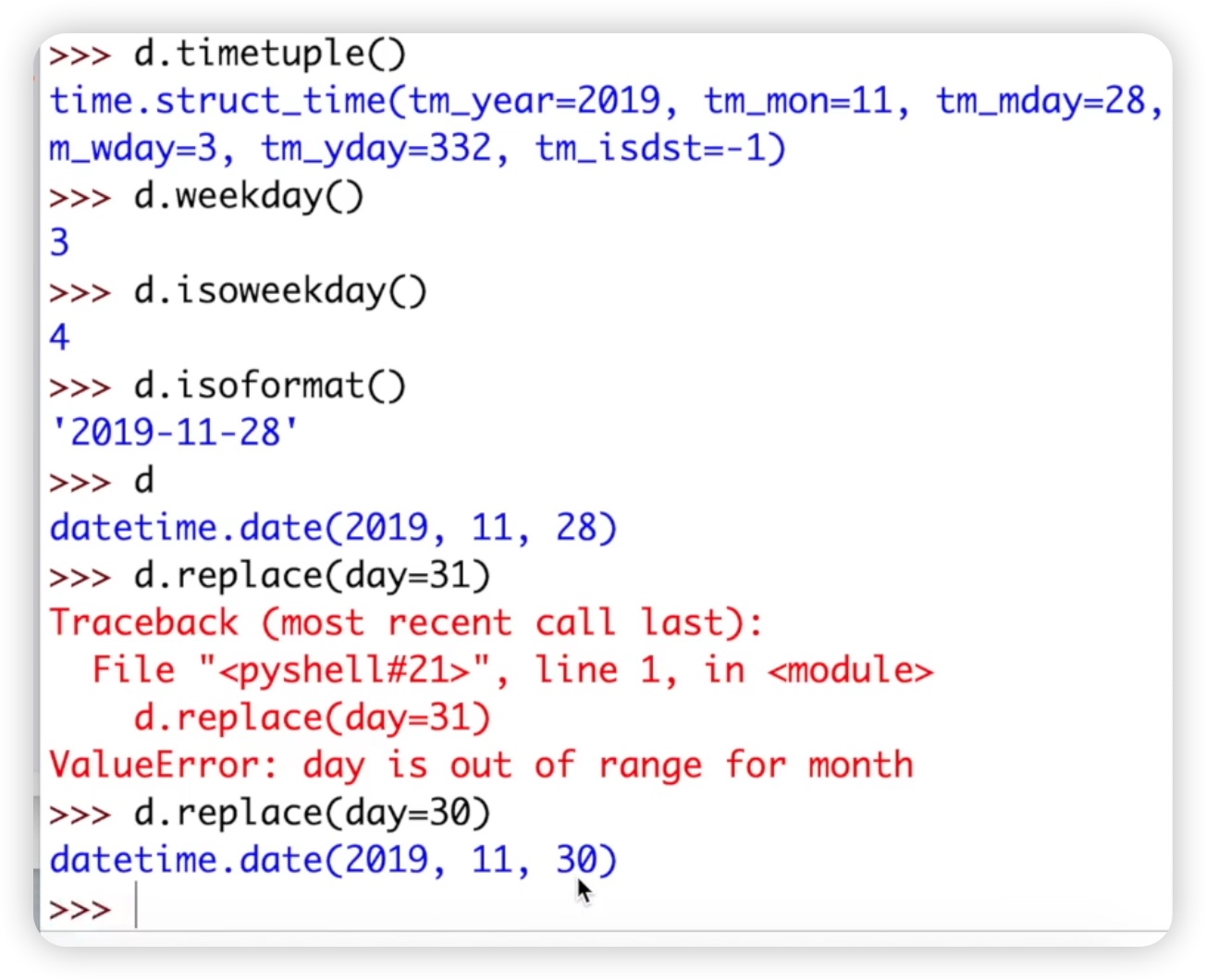
接着,我们来看实例方法。实例对象已经创建好了,直接调用它的方法即可。例如,d.timetuple方法将日期转换为时间元组,返回一个包含了年、月、日、时、分、秒等参数的时间元组。另一个方法d.weekday用于获取今天是星期几,返回的是从零开始计数的星期几,其中星期一对应着0。再来看d.isoweekday方法,它与weekday方法不同的是,它符合ISO标准,即星期一对应着1,星期日对应着7。最后一个方法是d.isoformat,它返回一个标准的时间格式的字符串,通常是年月日之间用斜杠分隔。还有一个实例方法d.replace,用于替换日期中的年、月、日等部分。我们可以通过调用d.replace方法来进行替换操作,例如将日期中的某一天替换为另一天。代码如下图:
- datetime类
接下来,我们再来介绍datetime类。datetime类是对日期和时间的一个综合,它的语法结构包含多个参数,如年、月、日、时、分、秒、微秒、时区以及fold。如下图:

可以看出,它是对date和time的一个集合。同样地,它也有类属性,包括最小值、最大值以及resolution(转换的一个单位)。如下图:

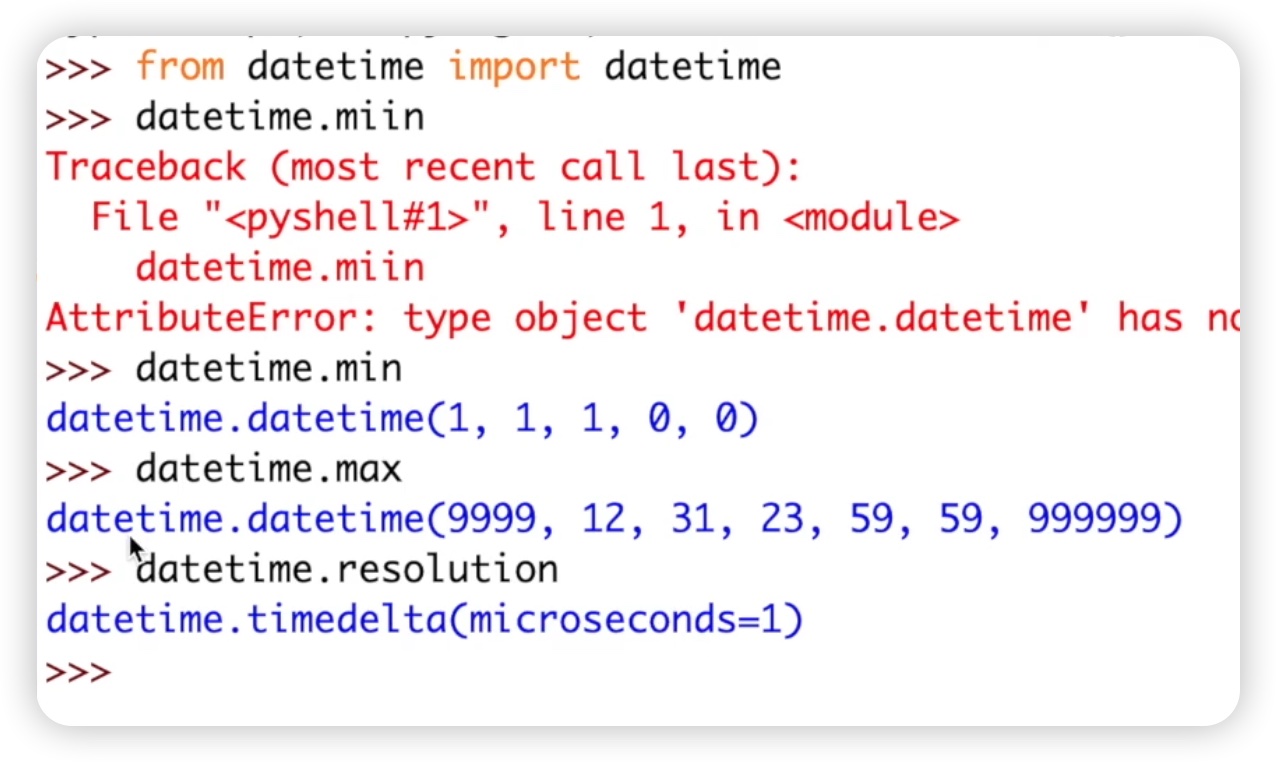
我们也在IDLE中进行演示。首先,我们导入datetime模块,然后直接调用datetime类的属性,如datetime.min、datetime.max和datetime.resolution,分别表示最小值、最大值以及转换的一个单位,单位是微秒。
接着是类方法,如下图所示:
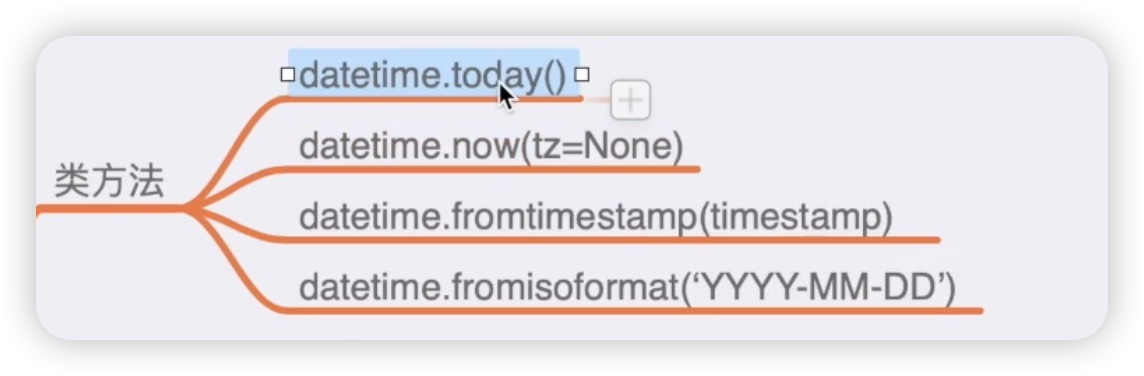
其中有一个today方法,可以获取今天的年、月、日、时、分、秒。我们在前面介绍date类的时候,也介绍过一个today方法,它能够获取的是年月日。而datetime的today方法,则能获取的是年、月、日、时、分、秒以及微秒。如果你只想获取日期,你就使用date类的today方法;如果你还想获取时间,那么你就使用datetime类的特定方法。此外,需要强调的是,当使用print函数输出时,结果是一个字符串,这是因为在使用print函�数的时候,系统会默认调用类下面的一个叫做__str__的方法。
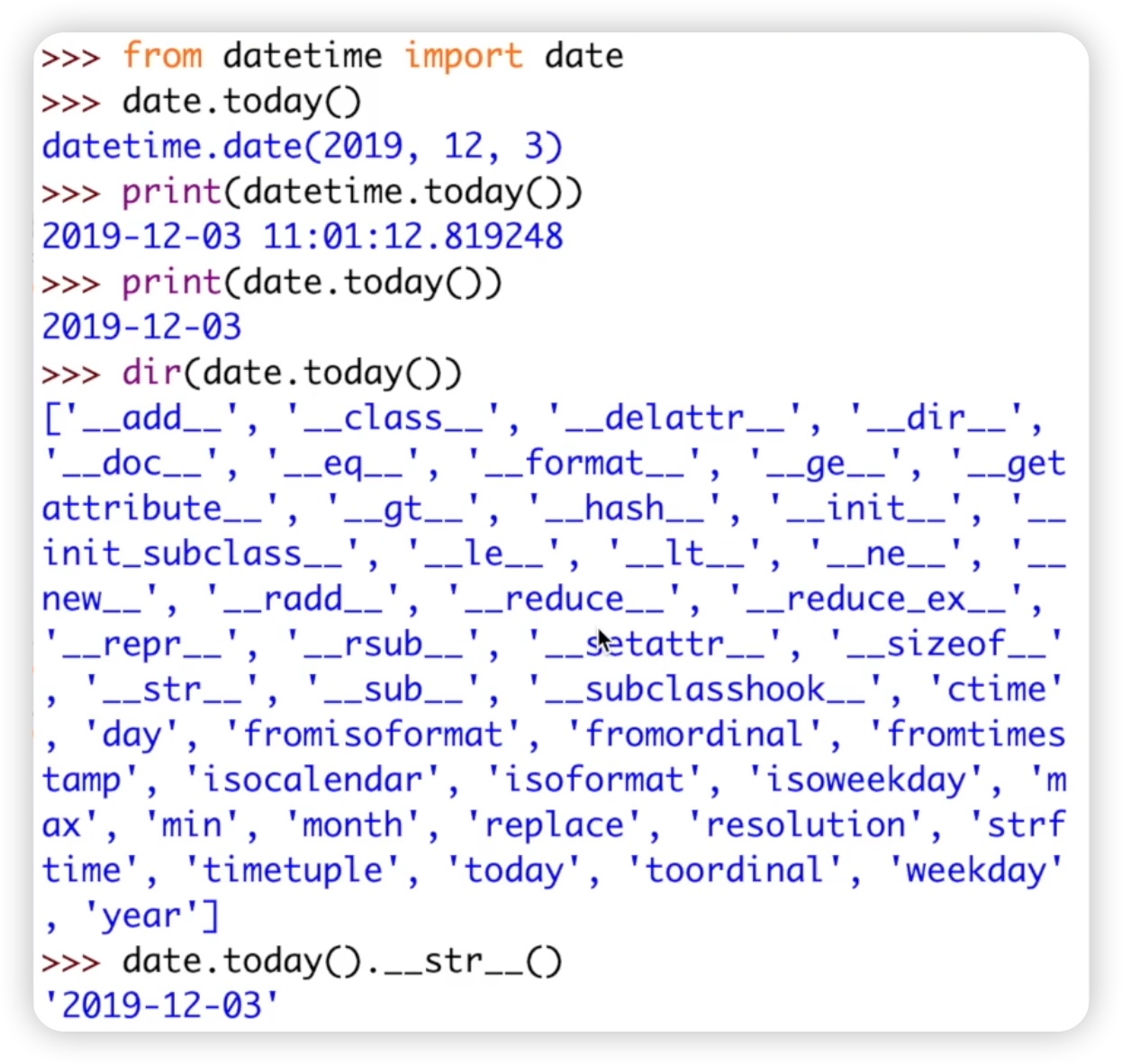
另外一个常用的方法是now方法,它也能获取当前的年、月、日、时、分、秒。它的输出结果与使用today方法的结果是一样的,都是年月日时分秒以及微秒。这是因为datetime.now方法有一个默认参数tz,也就是时区,如果这个时区参数设置为none,那么它就和today方法的输出结果一样。
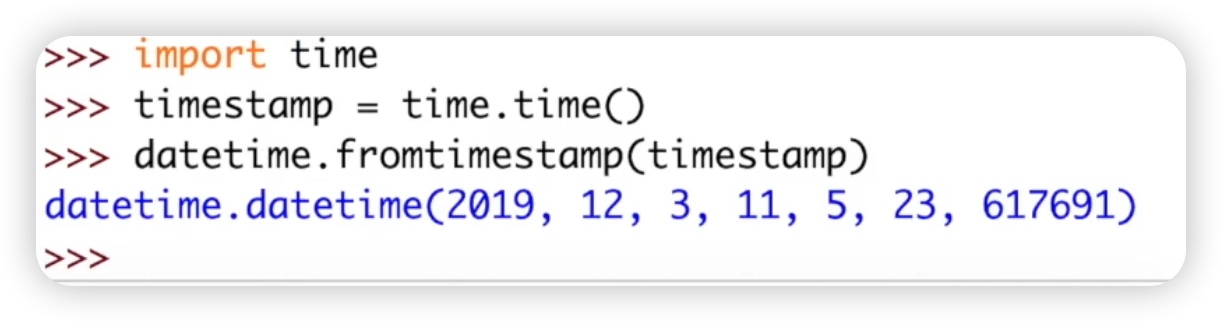
接下来的方法是fromtimestamp,它可以将时间戳转换为日期时间格式。我们首先需要导入time模块来获取时间戳,然后使用datetime.fromtimestamp(timestamp)来将时间戳转换为日期时间格式。代码如下图:
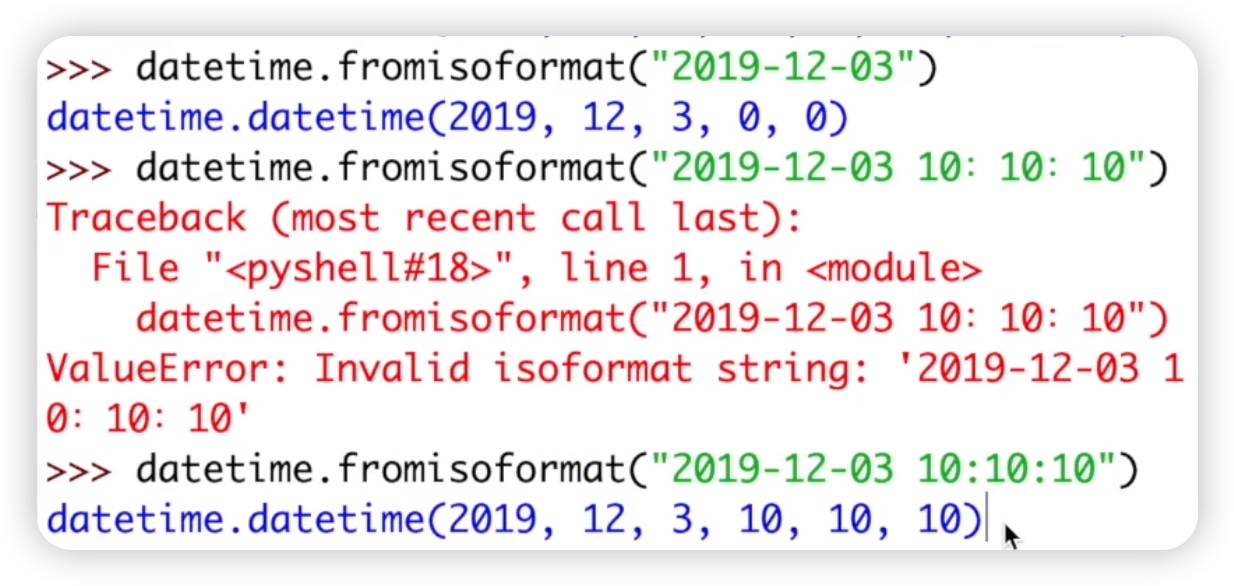
最后一个方法是fromisoformat,它的意思是将日期类型的字符串转化为datetime类型。这个方法需要传递一个参数,是一个符合ISO格式的字符串,比如"2019-12-03 00:00:00",结果就返回了一个datetime类型的数据,包括年、月、日、时和分。这是datetime类型的类方法。代码如下图:
接下来,我们再来看一下它的实例属性和实例方法。如下图所示:
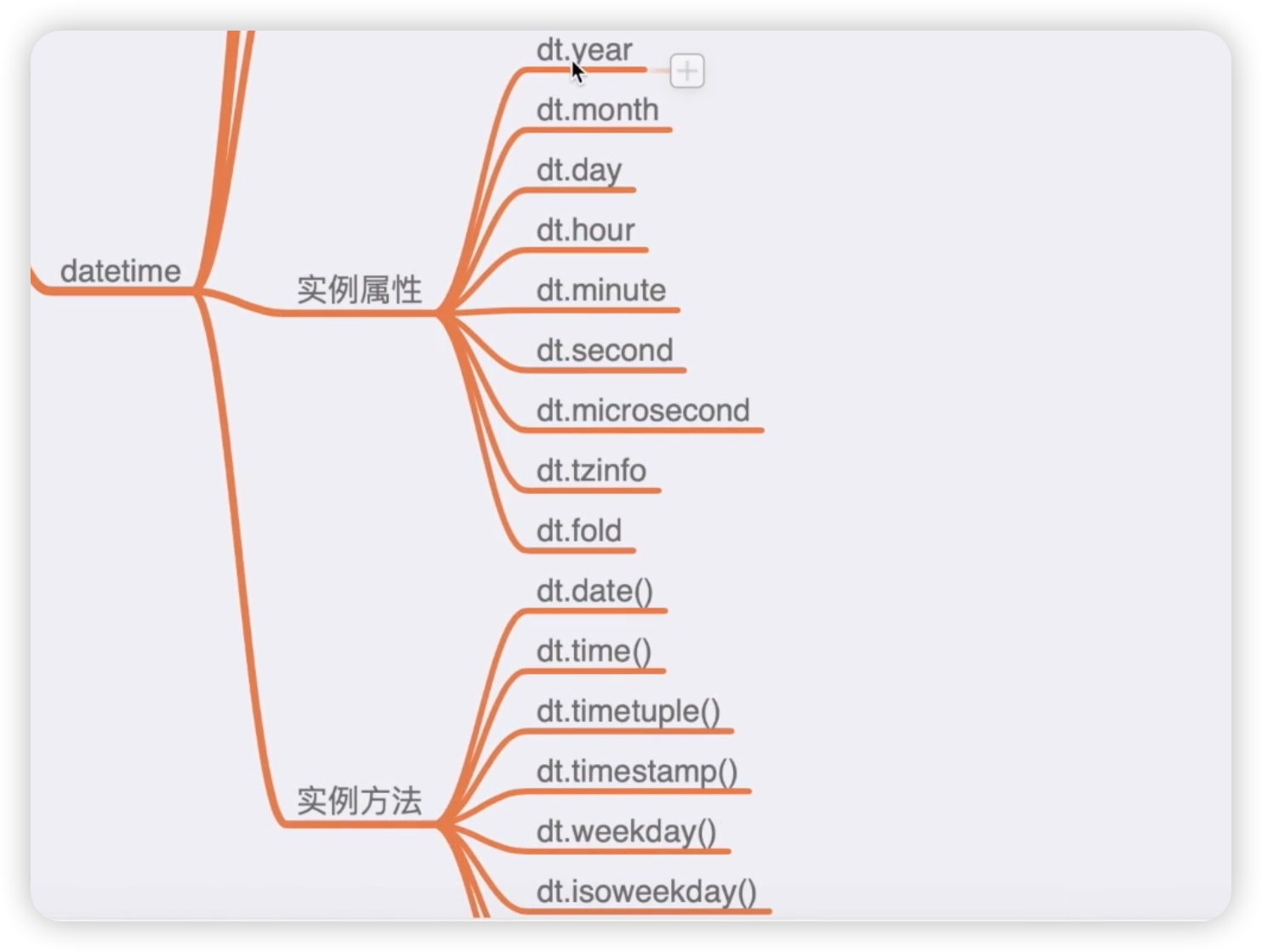
实例属性非常简单,获取实例对象以后,直接调用相关的属性来获取年月日时分秒这些参数等等。我们重点看了实例方法,比如dt.date获取日期,dt.time获取时间,dt.timetuple将日期时间转换为时间元组等等。代码如下图:
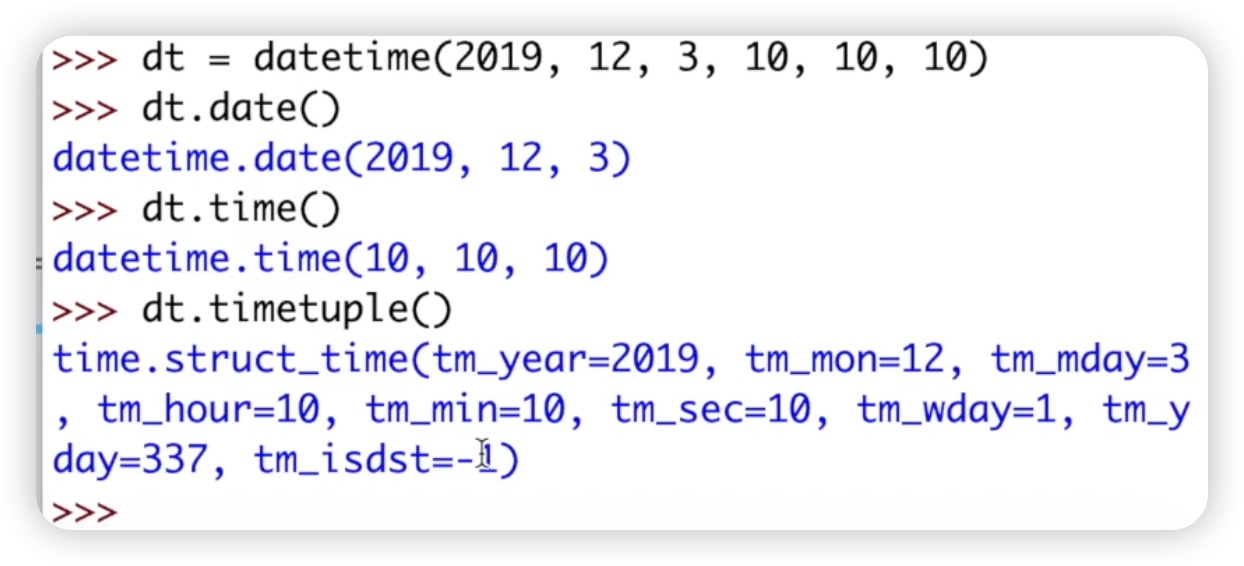
这些方法说明了一个问题,就是我们现在使用的datetime模块可以和其它模块进行相互的转化,比如datetime可以转化为date类、time类以及时间元组。转化完成以后,我们在前面讲解的相关的实例属性以及方法都可以使用了。所以说datetime类它是一个date和time的一个综合体。
- time类
接下来我们将深入介绍time类。首先,让我们先了解一下它的语法结构,然后再介绍相应的类属性、实例属性以及实例方法。如下图所示:

在实例化time类时,需要提供一些参数,包括小时、分钟、秒以及微秒。微秒和秒之间的关系是什么呢?一秒钟等于1000毫秒,而一毫秒等于1000微秒,因此一秒钟等于10的6次方微秒。还有一个参数是tzinfo,表示时区,默认为none。最后一个参数是fold,它的取值范围是0和1,用于消除一个歧义。这个参数是在Python3.6版本中加入的,用于消除与时令相关的歧义。关于tzinfo时区和fold这两个参数,我们平时不会经常使用,所以这里不再详细介绍。
除了使用构造方法外,还可以使用另一种方法,即time.fromisoformat函数来构造一个time类型的数据。这个函数接收一个字符串,表示一个标准的时间格式,包括时、分、秒。
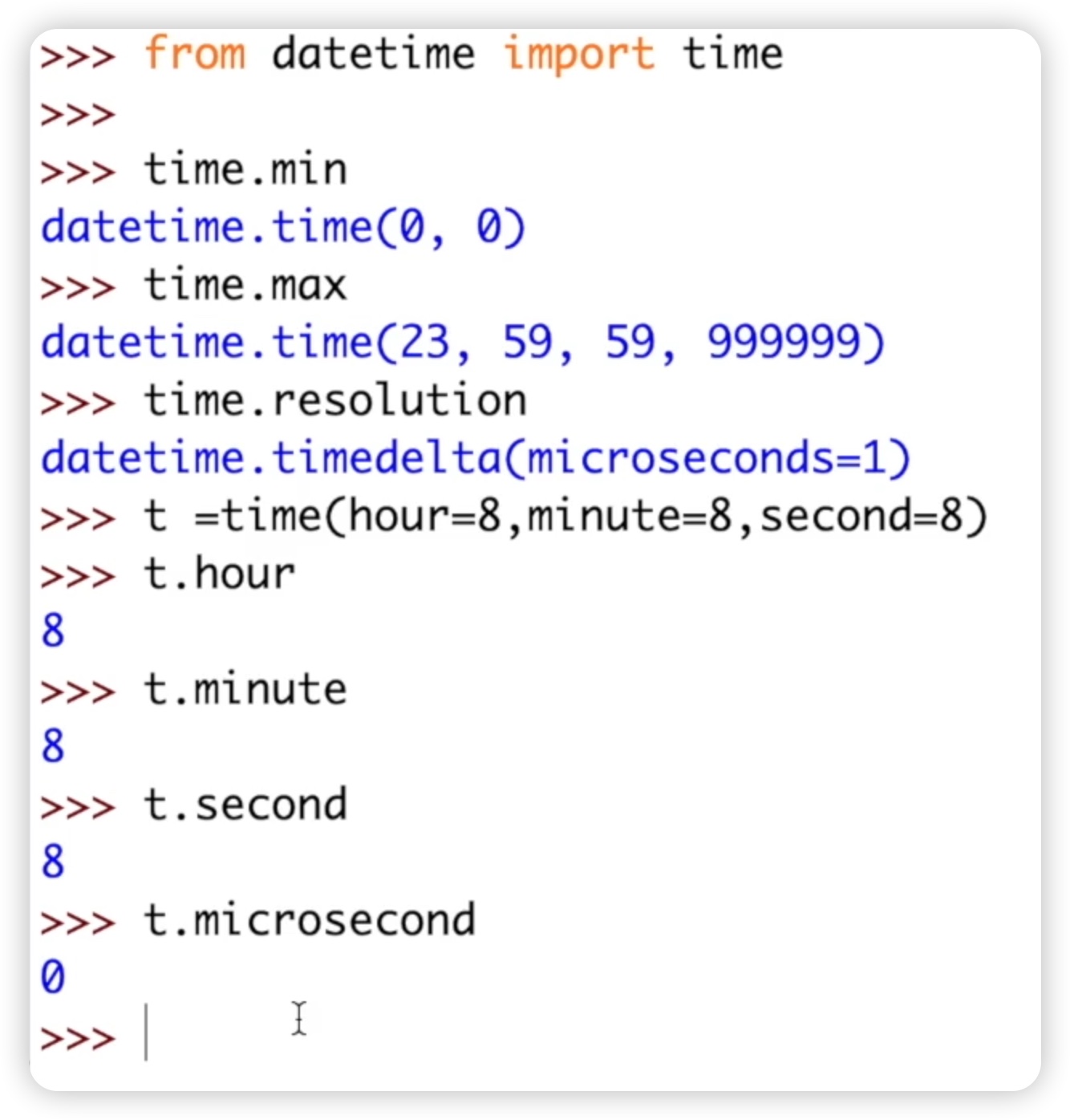
接下来我们来看time类有哪些属性?time.min用于获取最小值,time.max用于获取最大值,而time.resolution表示时间间隔的单位。时间单位是微秒。在idle中,我们导入time类并调用相关属性,可以得到最小值、最大值以及时间单位是微秒。代码如下图:
我们创建了一个实例t,其中包含了小时、分钟和秒,然后可以使用实例方法来获取时间的小时、分钟和秒数,还可以获取微秒数。同时,我们也可以使用实例方法来获取时区和fold参数。
- timedelt类
接下来,我们来看一下timedelta这个类。它是用于计算时间间隔的一个类,让我们了解一下它的使用方法。timedelta类的参数和我们之前介绍的类有所不同,包括天数、秒数、微秒数、毫秒数、分钟数、小时数以及日期数。如下图所示:

关于它的一些属性和方法,我们在这里就不再详细介绍了,主要看一下它是如何计算时间间隔的。我们需要导入timedelta类。假设我们想要计算两个日期之间的差异,我们首先获取今天的日期。为此,我们需要再次导入datetime模块并调用date类。然后,我们可以使用date.today()方法来获取当前日期。这样,我们就得到了一个日期格式的当前日期,例如2019年12月3日。代码如下:
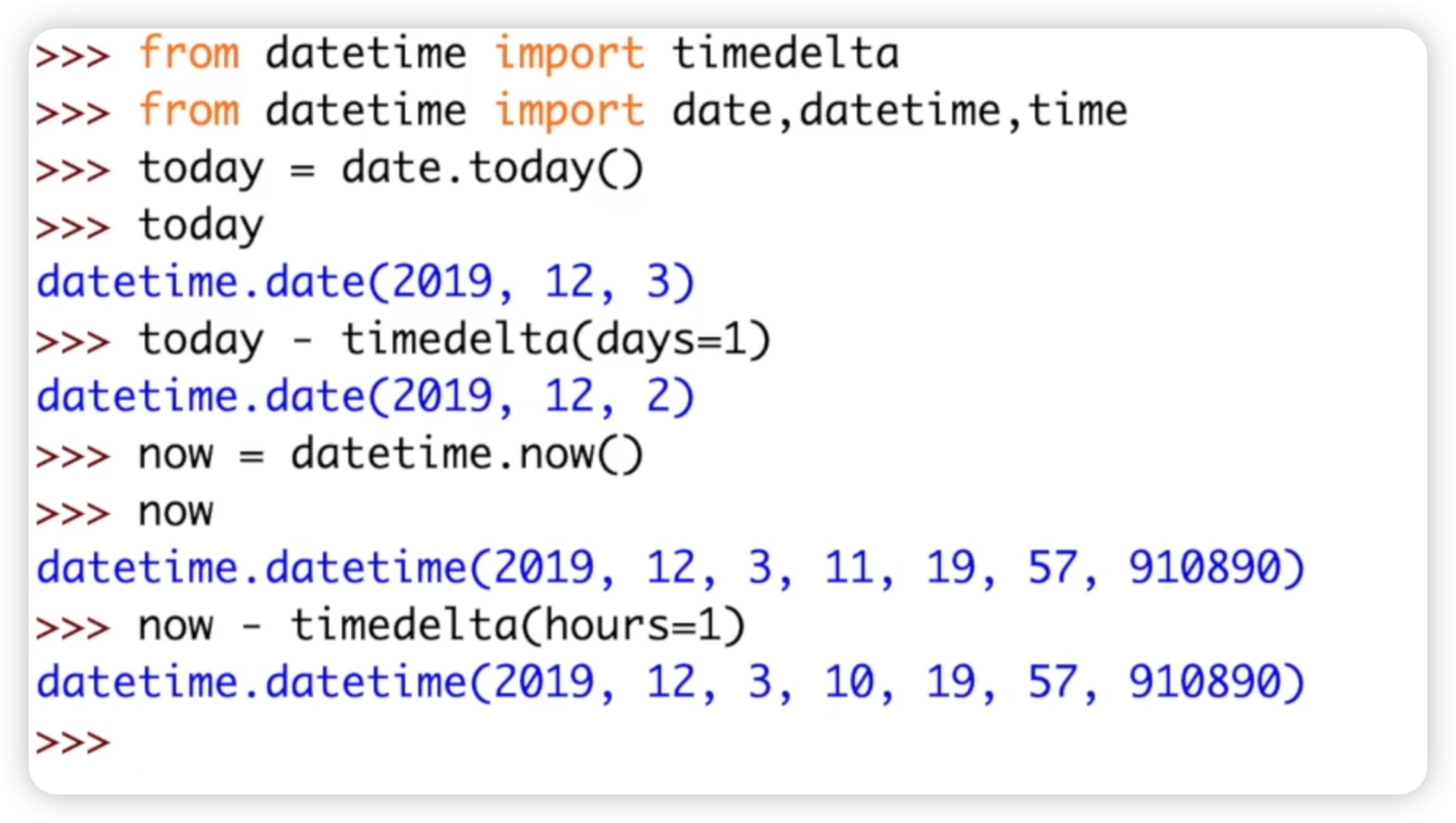
如果我们想要获取一天前的日期,我们可以这样计算:使用today()方法减去timedelta(days=1),表示时间间隔是一天。这样,就可以得到一天前的日期,即2019年12月2日。同样的,我们也可以计算一小时前的日期。首先,我们设置一个变量now,并使用datetime.now()函数来获取当前的日期和时间。接着,我们可以使用now减去timedelta(hours=1),表示时间间隔是一小时。这样,就可以得到一小时前的日期和时间。
常用内置模块calendar
在本节中,我们将介绍与日期相关的最后一个模块,即日历模块calendar。大家对日历都很熟悉。我们先来看一下calendar模块的文档。在数据类型部分,我们可以找到与日历相关的函数。如下图所示:
这个模块的文档内容非常丰富,包含了很多类和方法。我们将通过代码来演示它的使用。要使用calendar模块,首先我们需要导入它。我们导入calendar模块,然后直接调用calendar.month函数,让大家感受一下如何用Python生成一个日历。我们生成了2019年12月份的日历,并通过print输出。代码如下:
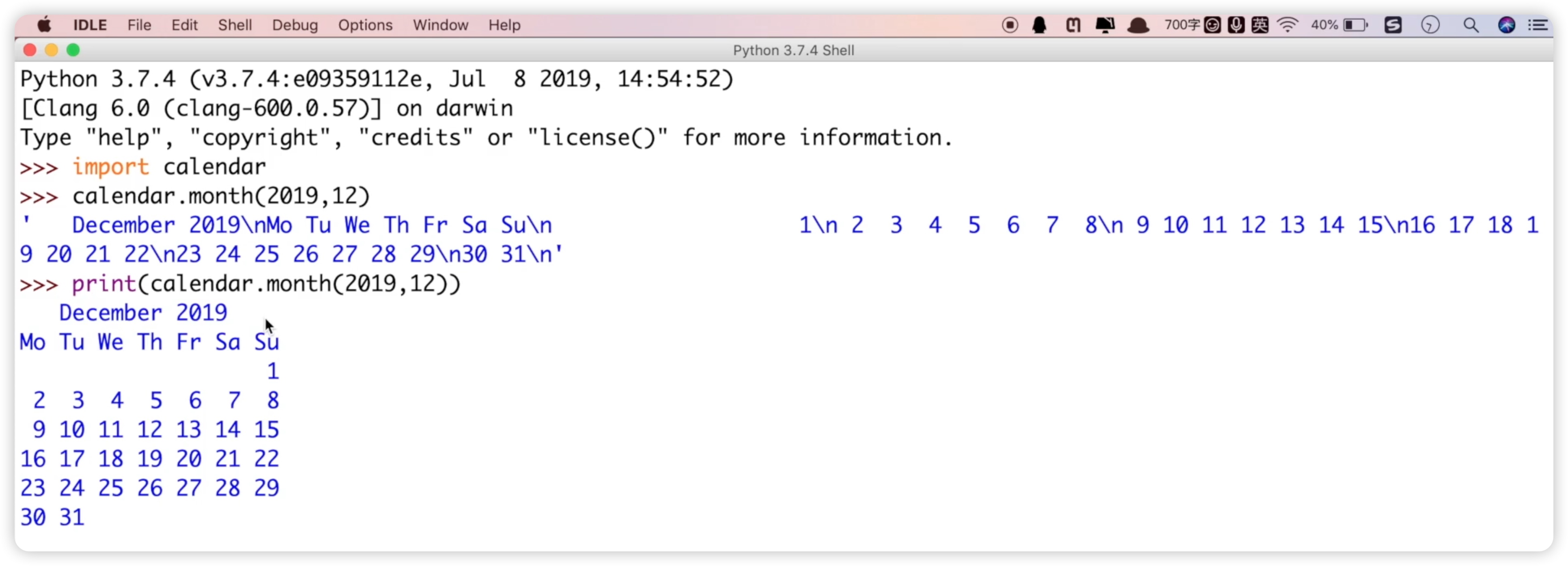
我们还可以设置日历的样式。通过添加参数来设置列的宽度和每行显示的周数,我们可以调整日历的样式。代码如下:
# 导入calendar模块,用于处理日期和日历相关功能
import calendar
# 调用calendar模块中的month方法,用于生成指定年月的月历
# 参数1:年份 (2019)
# 参数2:月份 (12)
# 参数3:日期之间的宽度 (3),即每个日期之间的间隔
# 参数4:每周的天数 (1),即每行显示的天数,默认为3
print(calendar.month(2019, 12, 3, 1))
此外,我们还可以输出某一年的日历,同样可以设置样式,使其更加清晰易读。
# 导入calendar模块
import calendar
# 使用calendar模块中的calendar函数生成指定年份(2024年)的日历并打印出来
print(calendar.calendar(2024))
日历模块不仅可以生成日历,还可以判断某一年是否为闰年。通过调用calendar.isleap函数,我们可以方便地判断一个年份是否为闰年。代码如下:
# 导入calendar模块
import calendar
# 调用calendar模块中的isleap函数,判断给定年份是否是闰年,返回True表示是闰年,返回False表示不是闰年
print(calendar.isleap(2016)) # 输出:True,2016年是闰年
print(calendar.isleap(2019)) # 输出:False,2019年不是闰年
接下来,我们介绍了两个比较实用的功能。第一个是计算某个月中有多少天,我们使用calendar.monthrange函数来实现。代码如下:
# 导入calendar模块
import calendar
# 调用calendar模块中的monthrange函数,获取指定年份和月份的第一天是星期几以及该月的总天数,返回一个元组
# 第一个元素是表示第一天是星期几的数字(0代表星期一,6代表星期日)
# 第二个元素是该月的总天数
print(calendar.monthrange(2024, 12)) # 输出:(6, 31),2024年12月份的第一天是星期日,该月共有31天
这个函数返回一个包含两个元素的元组,第一个元素表示星期几,第二个元素表示该月的长度,即有多少天。
第二个功能是获取一个月中每一天对应的星期。通过调用calendar.month函数,代码如下:
# 导入calendar模块
import calendar
# 调用calendar模块中的monthcalendar函数,获取指定年份和月份的日历,并以二维列表的形式返回
# 外层列表中的每个元素代表一个星期,内层列表中的每个元素代表该星期对应的日期(0表示该日期不属于当前月份)
print(calendar.monthcalendar(2024, 12)) # 输出一个二维列表,表示2024年12月份的日历
输出结果:
[[0, 0, 0, 0, 0, 0, 1], [2, 3, 4, 5, 6, 7, 8], [9, 10, 11, 12, 13, 14, 15], [16, 17, 18, 19, 20, 21, 22], [23, 24, 25, 26, 27, 28, 29], [30, 31, 0, 0, 0, 0, 0]]
此外,我们还介绍了如何输出日历的HTML格式。通过调用calendar.HTMLCalendar类,我们可以生成相应格式的日历文本。代码如下:
# 导入calendar模块
import calendar
# 创建一个HTMLCalendar对象
h = calendar.HTMLCalendar()
# 调用HTMLCalendar对象的formatmonth方法,生成指定年份和月份的HTML格式的日历
# 输出结果是一个字符串,表示2024年12月份的日历,以HTML格式呈现
print(h.formatmonth(2024, 12))
最终,我们可以在浏览器中解析HTML格式的日历,生成可视化的日历页面。
常用内置模块json
在本节中我们将介绍一个新的内置模块,即json模块。JSON代表JavaScript对象表示法,是一种数据格式,最初用于JavaScript。由于JSON易于人类阅读和编写,同时也易于机器解析和生成,因此成为了广泛应用的数据交换格式,不再局限于JavaScript。在不同编程语言之间进行数据交换时,JSON作为一种通用格式发挥了重要作用。如下图所示:

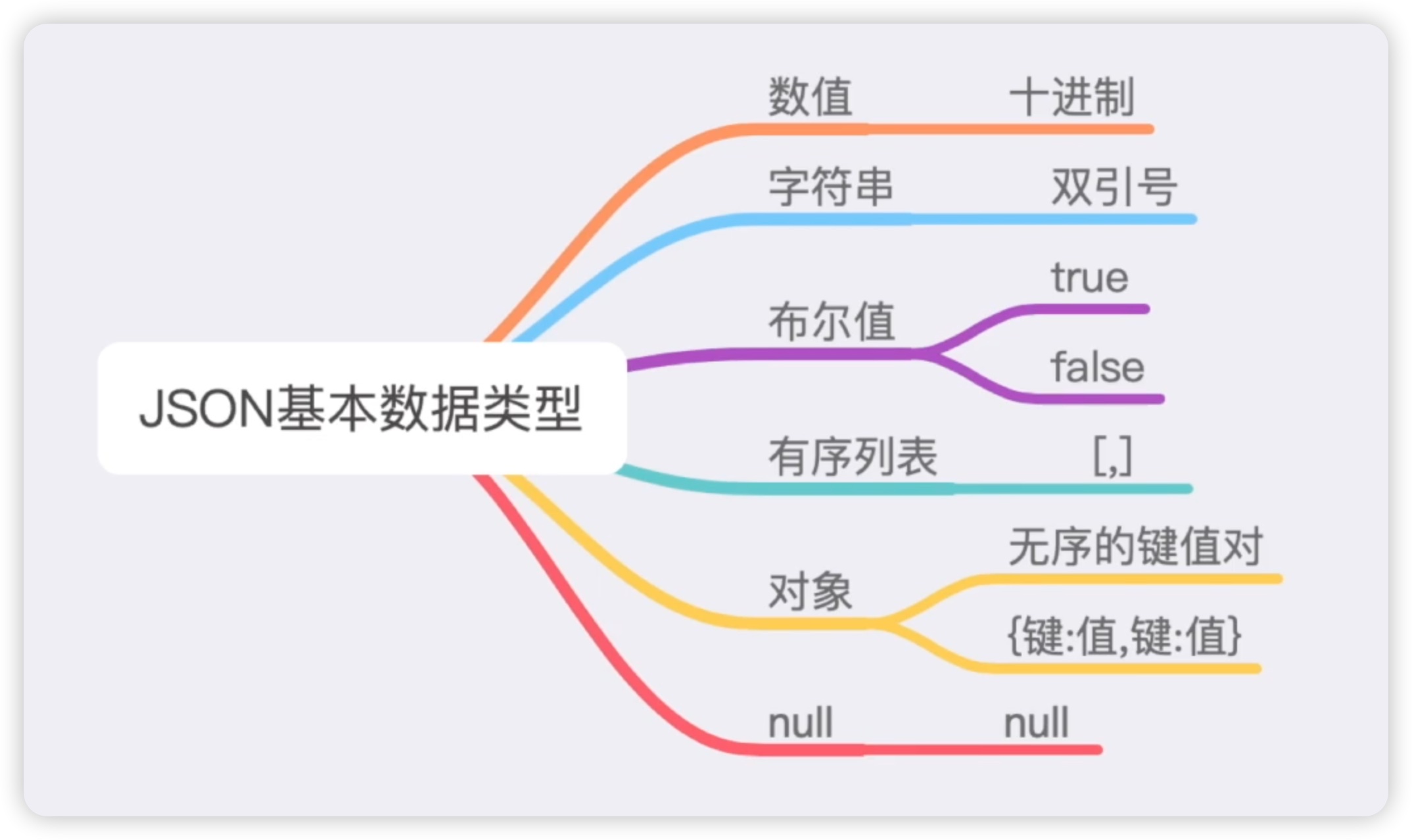
JSON有一些基本的数据类型,包括数值(十进制的整数和浮点数)、字符串(用双引号包裹)、布尔值(true和false)、有序列表(使用中括号表示)、对象(无序的键值对,类似于Python中的字典),以及null类型(表示为空)。JSON数据的格式非常灵活,易于理解和使用。
JSON模块在Python中提供了方法来实现JSON格式数据与Python数据类型之间的相互转换。通过json模块,我们可以将JSON格式数据转化为Python数据类型,以及将Python数据类型转化为JSON格式数据。JSON模块中最常用的方法包括dump、dumps、load和loads。其中,dump和dumps用于将Python数据转化为JSON格式数据,load和loads用于将JSON格式数据转化为Python数据。如下图所示:

要将Python数据转化为JSON格式数据,我们可以使用dump或者dumps方法。dump方法将Python数据转化为JSON格式数据,并将其存储到文件中。dumps方法将Python数据转化为JSON格式数据,并以字符串的形式返回。load和loads方法则用于将JSON格式数据加载为Python数据类型,分别用于从文件中加载和从字符串中加载。
下面我们将演示如何将JSON格式数据转换为Python格式数据。首先,我们需要在代码中新建一个文件夹,命名为"json",然后创建一个Python文件,命名为"transform",表示转换的意思。首先,我们导入json模块,然后使用dir(json)查看其可用方法。代码如下:
import json
print(dir(json))
在输出的方法中,我们看到了一些常用的方法,包括dump、dumps、load、loads以及编码器和解码器。
接下来我们将演示如何将一个字典转换为JSON格式数据。我们定义了一个字典,包含了姓名、年龄和爱好,然后使用json.dumps将其转换为JSON格式的字符串。代码如下:
import json
# 创建一个空字典
dict_value = {}
# 给字典赋值
dict_value['name'] = 'andy'
dict_value['age'] = 18
dict_value['hobby'] = ['basketball', 'football', 'baseball']
# 输出字典内容
print(dict_value)
# 输出字典的数据类型
print(type(dict_value))
# 将字典转换为JSON格式的字符串
json_str = json.dumps(dict_value)
# 输出转换后的JSON格式字符串
print(json_str)
# 输出转换后的字符串类型
print(type(json_str)) # JSON格式字符串的数据类型
输出结果:
{'name': 'andy', 'age': 18, 'hobby': ['basketball', 'football', 'baseball']}
<class 'dict'>
{"name": "andy", "age": 18, "hobby": ["basketball", "football", "baseball"]}
<class 'str'>
输出结果显示了字典和JSON格式字符串的区别,同时也展示了它们的数据类型,一个是字典类型,另一个是字符串类型。需要注意的是,虽然我们称之为JSON格式,但在Python中并没有专门的JSON数据类型,所以它实际上是字符串类型的数据。
接着,我们演示了如何将JSON字符串转换回字典格式,使用的是json.loads函数。代码如下:
import json
# 导入json模块
# 定义一个JSON格式的字符串
json_str = '{"name":"andy","age":18}'
# 使用json.loads()方法将JSON字符串加载为Python字典,并赋值给result
result = json.loads(json_str)
# 输出加载后的结果的数据类型
print(type(result))
输出结果:
<class 'dict'>
此外,我们提醒了大家在创建JSON格式字符串时,外层应使用单引号,内层使用双引号,这是JSON格式的要求。如果反过来,会导致错误。
接下来,我们展示了如何将JSON数据存储到文件中,使用的是json.dump函数,代码如下:
import json
# 字典转化为JSON格式
# 创建一个空字典
dict_value = {}
# 给字典赋值
dict_value['name'] = 'andy'
dict_value['age'] = 18
dict_value['hobby'] = ['basketball', 'football', 'baseball']
# 输出字典内容
print(dict_value)
# 输出字典的数据类型
print(type(dict_value))
# 将字典转换为JSON格式的字符串
json_str = json.dumps(dict_value)
# 输出转换后的JSON格式字符串
print(json_str)
# 输出转换后的字符串类型
print(type(json_str)) # JSON格式字符串的数据类型
# 存储到文件中
# 打开一个名为"json.txt"的文件,以写入模式"w"打开
file = open("json.txt", "w")
# 将字典数据写入文件中,以JSON格式存储
json.dump(dict_value, file)
现在我们使用的是相对路径,也就是说在我们这个transform.py这个文件的同一目录下,会创建一个叫做json.txt的文本文件。文本文件里的内容就是我们这里的dict_value的内容。好,现在我们来运行一下。看到这里果然生成了一个json.txt。我们打开它,这里面的内容就是我们的dict_value的内容。如下图所示:
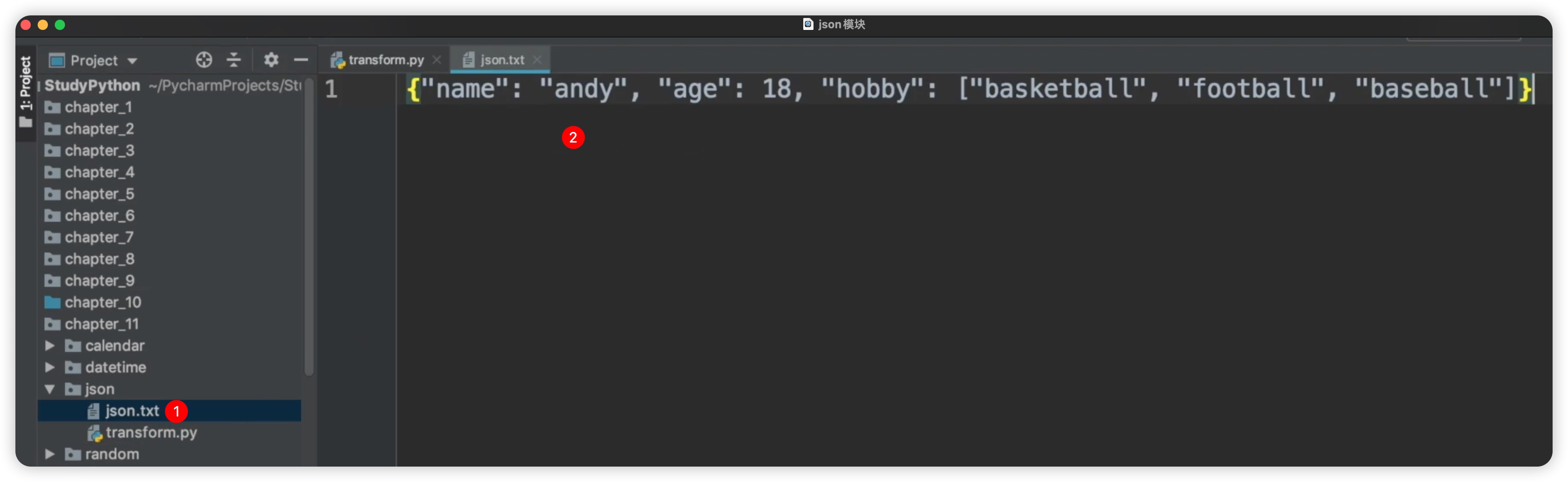
通过这样的对比,�大家就会知道dumps这个函数和dump函数,它们之间的区别:一个是以字符串的形式展示,一个是直接写入到一个文件中。
那如果我们是要从一个文件中来加载,也就是使用load函数。代码如下:
import json
# 将 JSON 字符串转化为 Python 字典
json_str = '{"name":"andy","age":18}'
result = json.loads(json_str)
print(type(result)) # 输出结果的类型为字典
# 从文件中加载 JSON 数据并转化为 Python 对象
file = open("json.txt", "r") # 打开名为 json.txt 的文件,以读取模式("r")打开
result = json.load(file) # 加载 json.txt 文件中的 JSON 数据
print(result) # 输出从文件中加载并转化的结果
看到输出的结果就是我们刚才的dict_value,也就是json.txt这个文本中的内容。